
Understanding Computers
2024-12-29

Exploration
This article is part of an exploration of the low-level details of computers.
Where is this going? I don’t know yet, but, I do know - from experience - that if I can draw sensible sketches of something, then I begin to understand it better and that I find it easier to explain. This is a form of “first principles thinking”[1].
Will there be more articles in this series? I don’t know yet. This is exploration, and, by definition, I don’t know where it will lead.
Comments and questions are most welcome.
What I Currently Believe
My gut says that we’re tangled up in complexity because we’ve been hanging onto the ideas of general-purpose, functional, shared memory, programming too long.
The indications are that we’re breaking out of that box. We’re using special-purpose circuitry, like GPUs, for advancing the state of the art, for example in heavy graphics (ostensibly for gaming) and LLMs.
There’s a lot of cruft that we added to CPUs and to general purpose programming languages that we don’t need anymore given that we can punt work to special-purpose circuitry.
What else could we be imagining if we stay out of the box that we’ve created for ourselves?
My gut says that general-purpose, functional, shared-memory, programming only covers something like 20%1 of what REMs (Reprogrammable Electronic Machines - aka “computers”) could be used for.
If we step back, there are plenty of “smells” in the way that we approach programming - tells that indicate that something is rotting.
A glaring example is the way that we deal with asynchronous behaviour. We invented clunky solutions to asynchronous behaviour like callbacks, then sync, await, etc., etc. This leads me to think that we’re pushing too hard in only one direction (overworking the general-purpose, functional, shared-memory paradigm) instead of addressing what we really want to accomplish.
Currently, I view hardware as, well, hardware. Not mathematics. Mathematics was invented as a way to help think things through using only pen and paper. REMs give us new choices for expression that aren’t as “flat” as paper. We can, now, think in 4 dimensions - x, y, z, t. We no longer need to flatten programs to fit the ink-and-paper model. Tools like Blender[2] make it possible to “write down” (express) and explore complex interactions that defy pen-and-paper-only modelling.
Our mathematical, pen-and-paper mindset has caused us to confuse “programming” with writing textual functions as lines of code. This approach hides the fact that sequencing is built into the notation - control flow can only go
Downwards to the next statement
Anywhere else using a function call or CPS2. But, when this happens, the sequencing “blocks” - the machine scribbles a bookmark onto a shared stack (a “return address”) then waits for control-flow to resume at that point. The mindset that everything must work in a clockwork, sequenced manner, is causing us pain when we try to express the architecture of truly asynchronous systems. Currently, we can only write down how islands of sequential code can act as callbacks when triggered by some asynchronous event, instead of being able to express - to “program” - how a system is composed of many of such islands.
I might be wrong - I reserve the right to change my mind.
Computer Basics
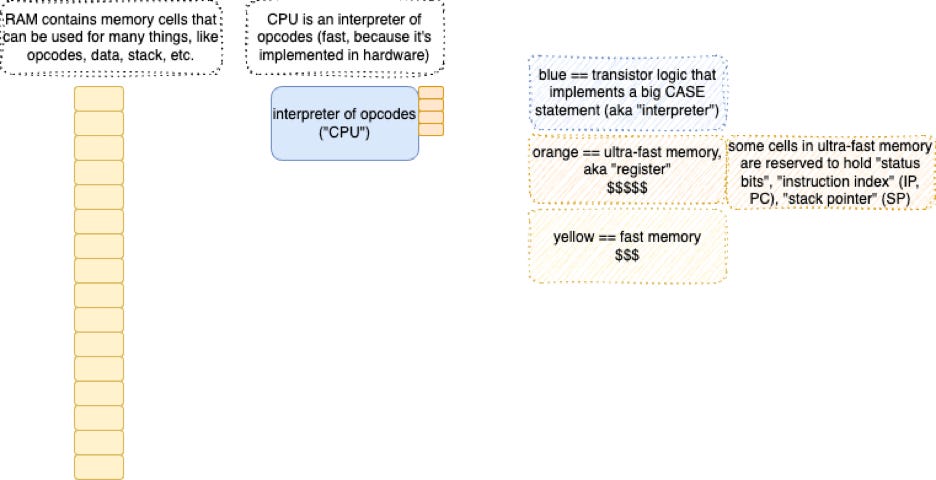
A REM - a “computer” - is just a ball of transistor logic attached to a ball of transistorized memory cells.
There are ways to make really, really fast memory cells, but, this co$ts a lot. We put only a few of these things into a CPU and call those memory cells “registers”.
We can make chips with lots of memory on them - kilobytes, megabytes, and, gigabytes of memory cells. These chips are a lot cheaper to manufacture. We call these things “RAM”3. The trade-off is speed. It takes longer for a CPU to touch a RAM cell than it takes to touch a register cell. One of the factors is the speed of light. The further a cell is away from the CPU, the longer it takes to touch the cell.
Moore’s Law has shrunk chips so much that we can put a lot more transistors on a chip, and, the transistors are more closely spaced, which makes everything just run a lot faster.
There’s nothing really special about transistors on chips, as Jeri shows in this video about how to make a transistor at home[3]. When we shrink transistors to be smaller and smaller, pesky things like dust particles loom larger and larger. A piece of dust in the wrong place can ruin a chip. So, to manufacture chips with zillions of tiny transistors on them, we need to worry about dust. This caused manufacturers to pay for and build “clean rooms”. Building a clean room is expensive and something you wouldn’t bother to do at home for a one-off project. The economies of scale make it affordable to build tiny chips in clean rooms, but, you have to sell a lot of chips to make this investment pay off.
Addressing, Pointers
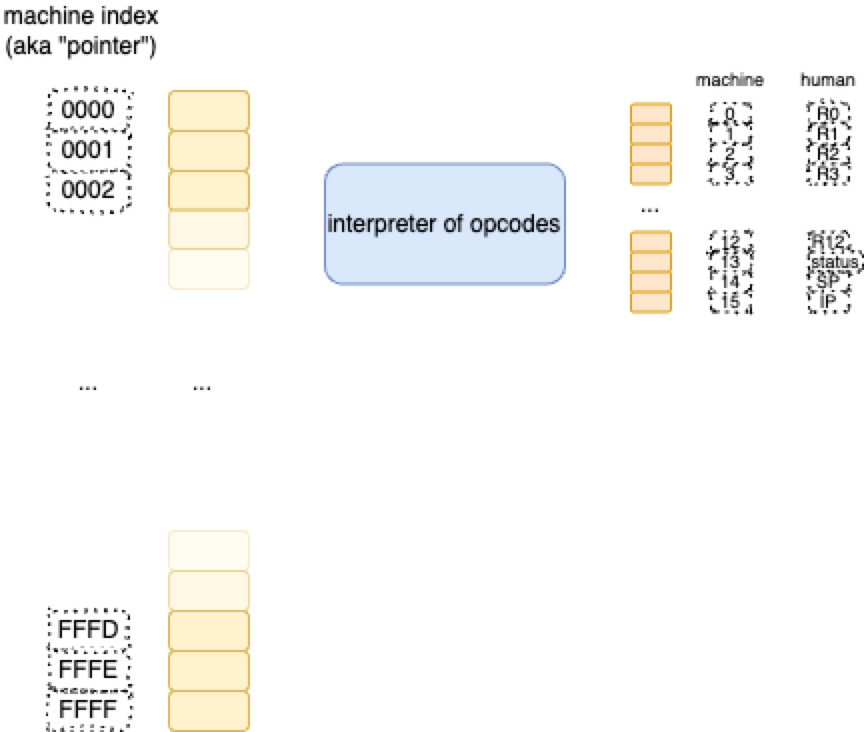
The ball of circuitry that makes up a CPU has to access memory locations. So, we lay out the balls of transistors that make up memory cells, in row-order. Basically, memory cells are arranged as arrays. There are two main banks of memory in a CPU
Registers
RAM.
Each memory cell is accessed by an index. We have invented different words that mean the same thing
Names, like R0, R1, etc. refer to the ultra-fast memory locations called “registers”
“Pointers” refer to the indices of fast memory called “RAM”.
In both cases, these things boil down to a number4, used as an index, along with a single wire (a “bit”) that indicates which bank of memory - register or RAM - needs to be addressed.
That’s it. There’s only 2 banks of memory, regardless of how much multi-tasking you program implements.
[Well, there might be more banks of memory, like caches, but we’ll skip over details like that for now].
Opcodes
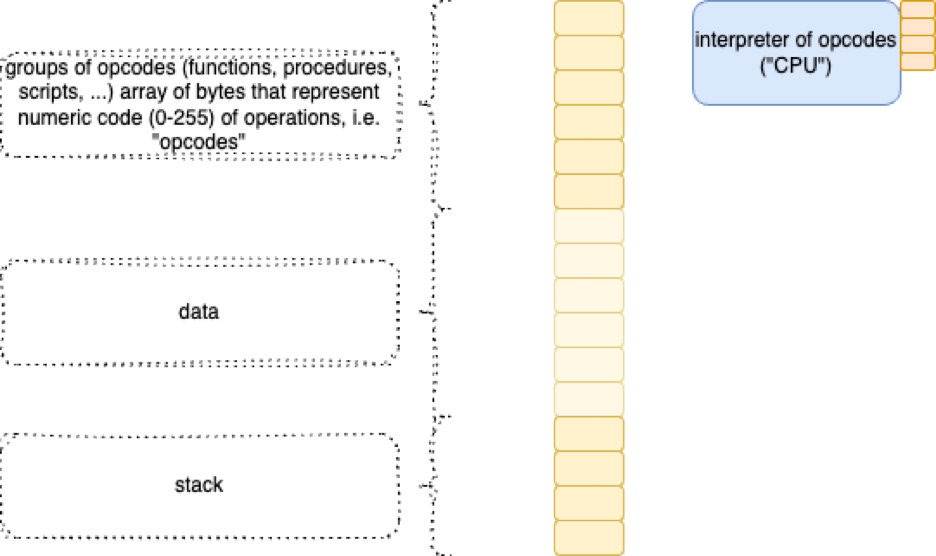
The ball of transistor logic inside the CPU accesses memory and acts an interpreter of what it finds in memory.
We programmers, tend to split up the “meaning” of the stuff inside of memory into roughly 3 big chunks:
Opcodes
Data
Stack
Data (2) is just stuff stored in memory cells. The CPU doesn’t bother to assume it knows what the data stuff is used for.
The CPU does, though, make assumptions about what’s in the other 2 sections.
The stack (3) is assumed to contain bookmarks - “return addresses” which are just indices of places in opcode space - and various other kinds of stuff, like parameters and return values and temporary values, and, etc. Note that “the stack” is really just an array of a mixed bag of stuff (“heterogeneous” array). The interesting part is that the CPU reserves the use of one of its registers to act as an index into the stack. Usually this register is given the name “SP” for “stack pointer”. Certain opcodes (see below) cause side-effects that bump the SP up or down automatically, instead of in a random indexing manner. The hardware can do such auto-bumping faster than if these actions were separated as stand-alone opcodes.
The opcode (1) space is assumed to contain bits that get interpreted as transistor-logic operations.
The CPU contains transistor logic to do various things, like suck data out of RAM, or to put data into RAM, or to add the contents of two registers together.
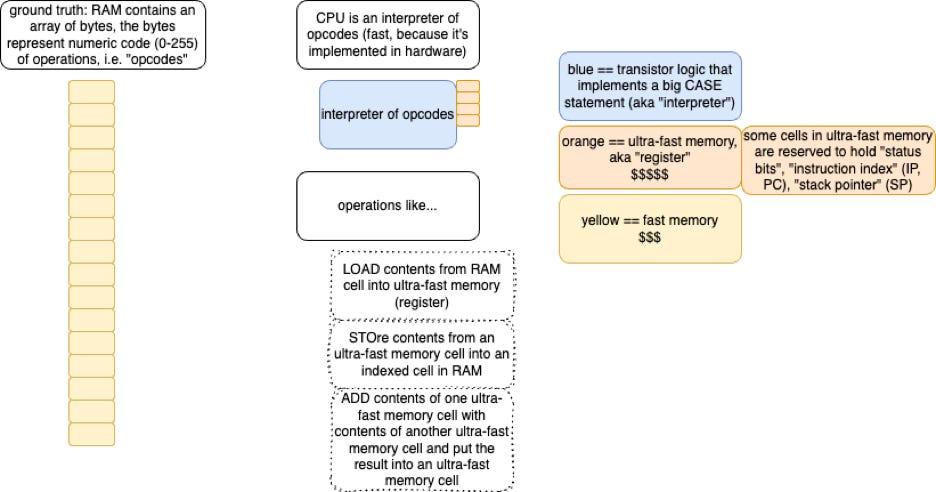
The ball of logic that constitutes the guts of a CPU, is just a big CASE statement, that interprets the meaning of every opcode - every set of bits in the “program”/“opcode” space of memory. The CPU is an interpreter.
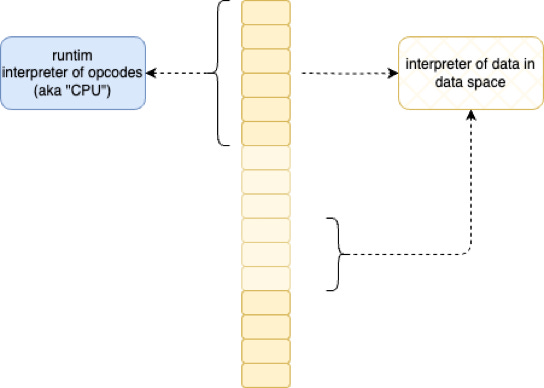
We have managed to confuse that word with bigger programs that we write. We use the word “interpreter” to mean blocks of bits that get double-interpreted by the hardware to interpret more blocks of bits,
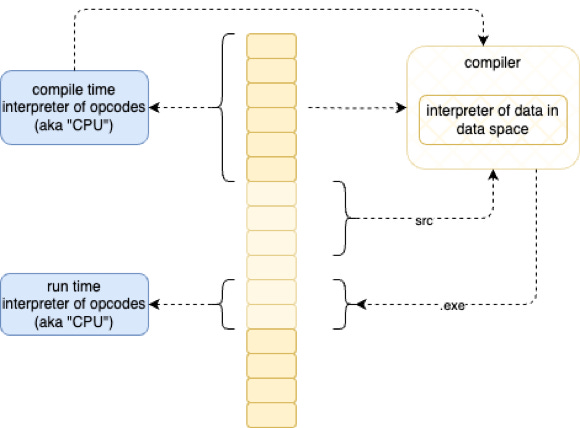
and, we use the “compiler” to mean “pre-processing optimizer” which does some of the double-interpretation work earlier before the work gets sent to the hardware interpreter in the hopes of amortizing some of the hardware-based interpretation across many runs of the same block of bits.
At first, we programmed computers using banks of switches.

https://commons.wikimedia.org/wiki/File:DEC_PDP-8,_Stuttgart,_cropped.jpg
{kind=link}
Later, we tagged each interesting combination of switch settings with 3-letter “words”, called “mnemonics” and made a transpiler called an “assembler” to map the 3-letter words into sets of bits.

https://en.wikipedia.org/wiki/Assembly_language#/media/File:Motorola_6800_Assembly_Language.png
Then, even later, we grouped 3-letter words into HLLs that mapped fancy “statements” like
a = b + c;

into groups of mnemonics
which then got transpiled into blocks of bits by the “assembler” auto-transpiler.
Bibliography
[1] First Principles Thinking from https://fs.blog/first-principles/
[2] Blender from https://www.blender.org
[3] Homebrew NMOS Transistor Step by Step - So Easy Even Jeri Can Do It from
See Also
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
The 20% is just a number I pulled out of the air. My point is that we’re using only a small slice of CPU power by thinking only in the general-purpose, functional, shared-memory paradigm. Writing “functions” isn’t all that there is to “programming”.
CPS is just GOTO in disguise. Deja vu all over again.
Random Access Memory.
Actually, what we call a “number” is just a pile of electrical signals arranged as a group of say 64 or 16 or 8 “bits”. Transistor circuits understand “bits”. Humans understand the concept of “numbers” made up of “bits”.