
SEXP Syntax in Ohm
2025-03-10

The previous article shows a syntax that fails if one tries to parse nested bracketed text.
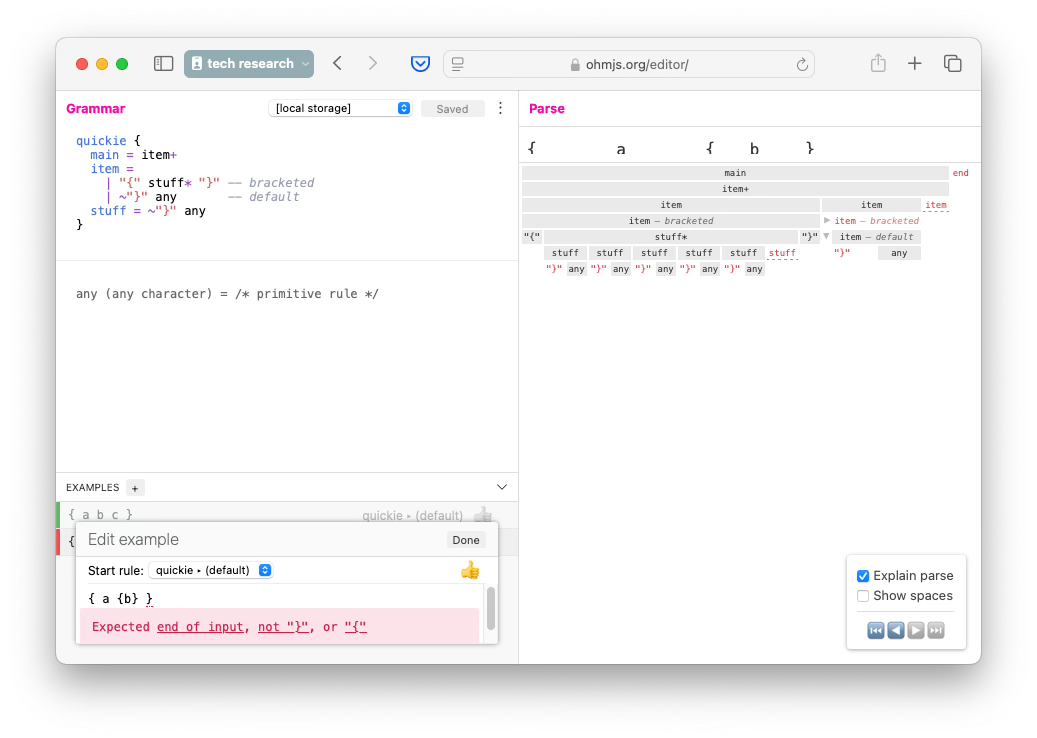
Let’s fix that by using recursion in the parsing syntax:
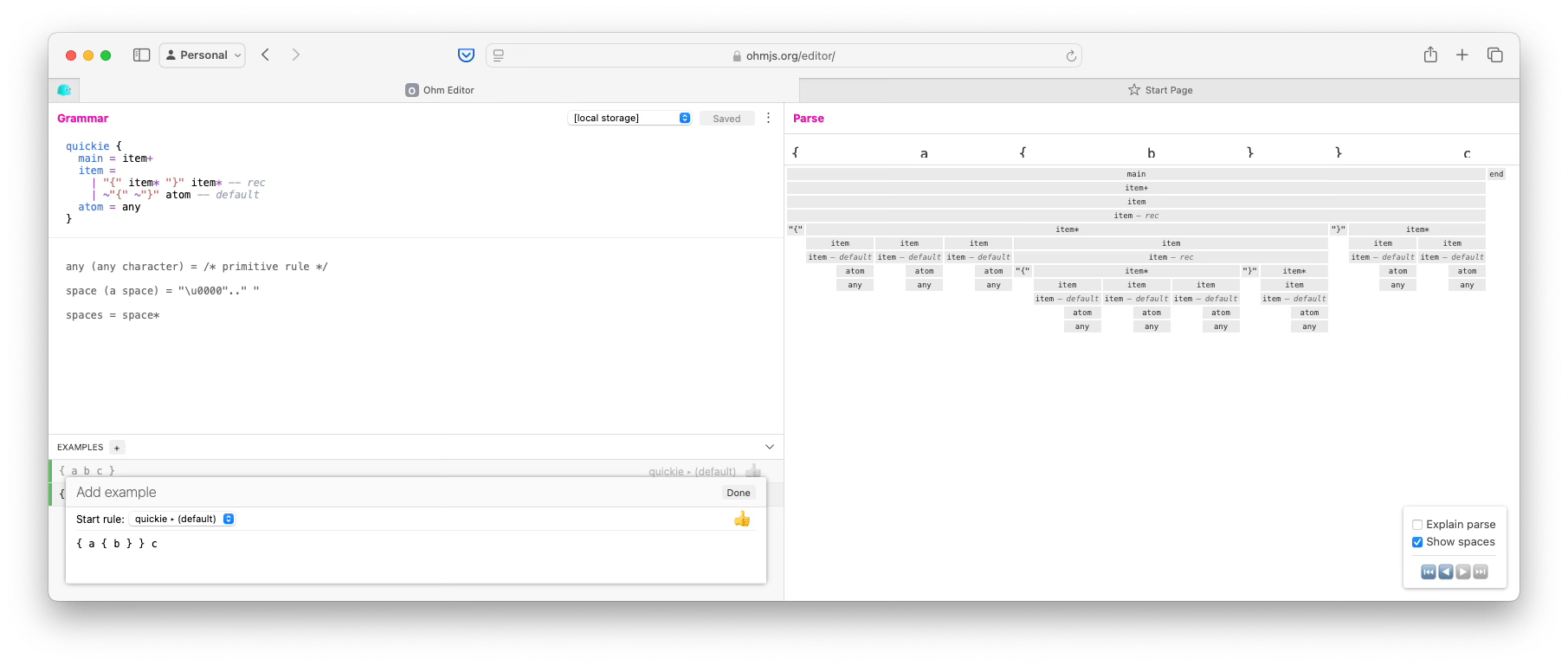
By the way, I’ve introduced something called an atom, which happens to be just any character in this step.
Now, let’s go all the way to a simplified Lisp syntax...
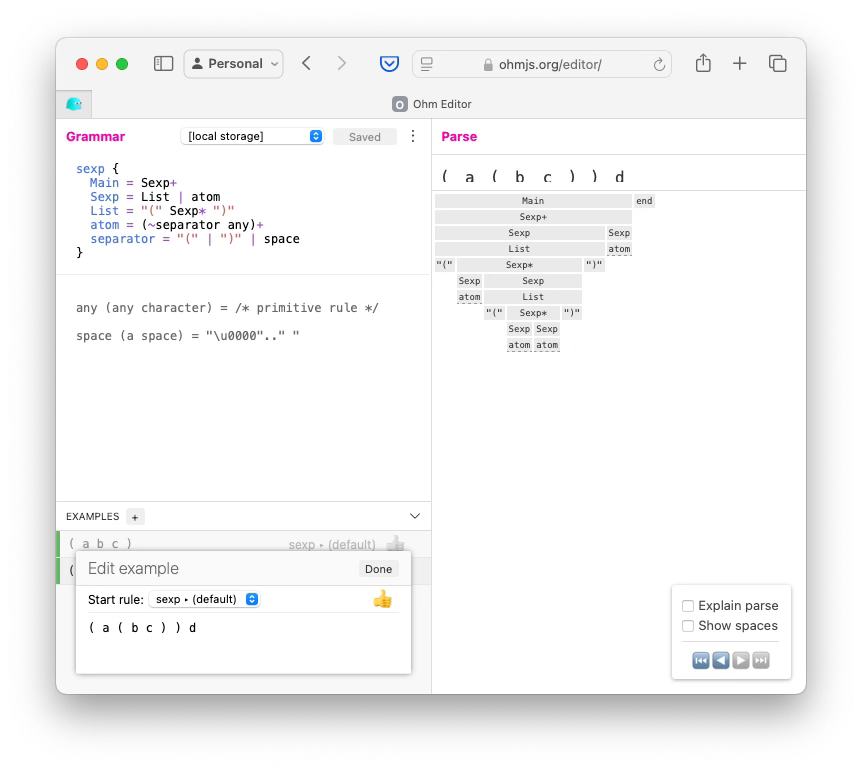
I’ve capitalized some of the Ohm rules. That turns on Ohm’s space-skipping feature. Capitalized rules are called syntactic rules, whereas uncapitalized rules are called lexical rules.
I’ve rewritten the grammar to look for 3 kinds of things:
Lists
Separators
Atoms.
The rule for List looks a lot like the item rule above. In particular, the List rule creates recursion (Sexp invokes List, and, List invokes Sexp).
A Sexp is either a List or an atom. The atom rule is lexical. It calls another lexical rule separator, so we need to consider spaces in it.
A third rule has been invented - separator.
In basic Lisp, there are very few separators:
Parentheses
Spaces
Single quote
Semi-colon for comments
Dots
Spaces are handled automatically in Ohm syntactic rules, but, the separator rule is written as a lexical rule, so we need to worry about checking for spaces in it.
In this, simplified grammar, I haven’t dealt with
dots
quotes
strings
numbers
semi-colons
How would you add these kinds of things to the grammar? Do you need to switch to lexical rules for everything?
I’m attempting to keep these examples simple, thus, I’m avoiding syntactic doo-dads that look complicated on first blush.
In less-basic Lisp, like Common Lisp, several operators are added for macros, vectors, read-tables, escapes, etc. Operators like:
#
,
`
|
\
spaces around dots
etc.
I’m not trying to build a full-blown Lisp syntax here, I’m only showing the beginnings of how one might start writing such a syntax.
Atoms are any run of non-separator characters. Most lispers like to use “-“ instead of “_” because it looks better and because they can get away with it. The Lisp interpreter says that everything is either a leaf atom, or a function call. “-” is just the name of a function that subtracts two numbers. It’s not a piece of infix syntax, like in other programming languages.
Aside - Parsing
In the early days, parsing wasn’t well-understood, so most syntax was kept to a minimum and was generally restricted to the use of ASCII characters. Tools like Ohm didn’t exist yet. Ohm is based on PEG parsing technology. CFG parsing technology preceded PEG. YACC, based on CFGs, didn’t exist, either, in the early days. In the early days, parsing was mostly done in a recursive-descent manner in hand-crafted assembler. PEG is closest to recursive-descent in flavour.
Top-down parsing, like recursive-descent parsing, differs from bottom-up parsing in spirit. Top-down says “so far, I’ve parsed all the way to here, what’s next?” Whereas bottom-up says “I’ve found this low-level thing, where does it fit into the overall structure?”.
Languages can be designed in a “rigorous” manner. CFGs have become popular, and, CFGs are based on rigorous language definition. Hand-crafted recursive descent parsers have more degrees of freedom. Hand-crafted recursive-descent can be use in a more loosey-goosey manner, but, that approach can create foot-guns.
Hand-crafted recursive-descent parsers and grammars “look” more natural and are easier to understand, whereas error-free CFG grammars twist the language grammar to fit the rules. If a grammar fits the rules, then the grammar can be automatically checked for niggly errors due to edge-cases. I’ve seen both styles used at once, e.g. CFG tools to check (“lint”) the grammar for erroneous edge-cases, but recursive-descent for actual implementation.
Writing rigorous, checkable grammars is more difficult and requires more time. The spread of CFG-based parsing tools has mostly eclipsed the idea of writing quickie parsers to do small, non-critical tasks, like bulk-editing, with some follow-on manual tinkering.
Most grammars are written in “BNF form”. BNF is one of the first DSLs that was invented. BNF is a DSL for the domain of parsing. YACC uses a BNF-like syntax and produces a state-machine. OhmJS uses a BNF-like grammar and produces an AST1 data structure that is walked by Javascript code (or, in my case, another DSL written in OhmJS, so that I may avoid having to explicitly write Javascript code).
PEG brings rigour back into recursive-descent parser generation. PEG grammars look like BNF grammars. We have been taught how to read and understand BNF. Now, with PEG (especially OhmJS), it is possible to loosen some of the screws and write rigorous parsers in a more convenient manner. Especially when OhmJS is coupled with Ohm-editor, which is like a convenient REPL for grammar development2.
OhmJS is basically top-down, whereas YACC is bottom-up. OhmJS brings PEG and recursive-descent-style thinking back into the realm of possibility. OhmJS can be used like a DSL for generating parsers and for doing quickie, one-off, knock-off tools. CFGs might work for that kind of thing, too, but CFGs require more careful planning, which tends to discourage exploratory programming. If you intend to use a CFG, you must already be pretty sure that you know what you want. There’s a phrase for that kind of thinking. It’s called the “waterfall method”.
See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com
Actually, after parsing source code, an AST is culled and becomes a CST, but, I quibble.
In fact, if I were developing a grammar for any PEG toolkit or library, I would use Ohm-editor first, then transliterate to the syntax required for the library. Getting a grammar right takes iteration. Iteration goes much, much faster when you can do it with Ohm-editor. The time wasted in rewriting the grammar one last time is swamped out by the time saved by using Ohm-editor to iterate in the first place.