
Programming and Macros in 2025
2025-07-16

In the beginning there were several options for creating programs.
The ideas behind MOAD and other forms of programming were ignored and a path consisting of 1400's Gutenberg type-setting (parentheses instead of vinculums) and 1960s hardware limitations (ASCII and QWERTY) were summarily chosen as the one-and-only-true-path for programming. Ironically, hardware in 2025 doesn't have the same limitations as 1960s hardware, but this fact is ignored and we stick to "we've always done it this way" thinking.
It was discovered that equations written in Gutenberg typesetting format, such as a + (b * c), could be internally represented as data structures called ASTs. ASTs are drawn on paper as 2D diagrams, such as
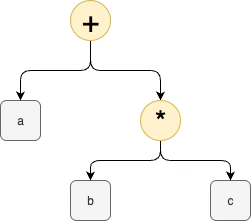
then compressed into Gutenberg typesetting 1D notation (text) using apps created for program developers. These apps were given the name parsers. A DSL, called BNF was invented to allow writing these diagrams in 1D form using ASCII and QWERTY hardware, regardless of the fact that ASTs are generally represented in textbooks as 2D diagrams. Further over-specification and bloatification of these apps was introduced with the invention of CFG parsing techniques. Around 2004, some of the over-specification and bloatification of CFGs was relaxed by the invention of PEG parsing techniques. This has since been enhanced through the invention of tools like Ohm, especially OhmJS and Ohm-editor. Ironically, instead of extending parsing into the realms of 2D and 3D and 4D notation, Ohm continues the tradition of incrementally improving upon 1D BNF-style notations.
[Aside: in 2025, we can use tools like drawio and Excalidraw to create drawings of figures that overlap. These tools crush 2D drawings down to 1D textual notation like graphML, SVG, XML which can be processed by the current set of 1D parsing tools, like Ohm, YACC, etc. But, we generally don't bother to do this. We could build 2D programming languages, but, we don't.]
The textbook format for the expression a + (b * c) is the AST diagram
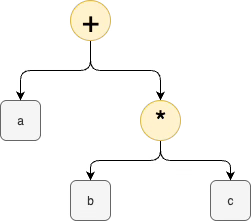
This AST can be reduced to Gutenberg typesetting notation as (+ a (* b c)). This is Lisp. Programming in Lisp is the same as programming with ASTs. Lisp has no "syntax". Lisp code consists of manually-written ASTs. Lisp code is prefix-only. Lisp code does not use infix syntax. Many programmers hate this textual notation. Some programmers love it. The "power" of Lisp is that the language comes with a bunch of built-in AST operators, such as CAR, CDR, CONS, and a tokenizer called the lisp reader with tokens called symbols. This power was used to spark the invention of macros, i.e. transpilers from ASTs to other ASTs. Incremental bloatification of the concept of macros came with the advent of hygienic macros which created a heavy-weight representation of a once-simple concept for the sake of nit-picky analysis and the one language to rule them all syndrome. Hygiene is only a problem if the concept of macros is embedded in a single language that conflates production programming with macro programming, instead of separating the concepts apart using staged computation and staged workflows. Again, the one language to rule them all meme is based on 1960s biases, instead of what is easily possible in 2025.
Lisp macros work because Lisp inhales programs as text but converts the text into internal form - lists (aka ASTs).
Can we invent the power of Lisp-like macros for infix, text-based, 1D programming languages? I argue that we have the tools in 2025 and that, yes, we can use these tools to create macros for text-based languages. My current favourite tool is what I call t2t. This is based on
OhmJS for the front end and
a custom SCN (little-DSL) for rewriting. This custom SCN is, also, based on the "grammar" for the incoming text / language / markdown / whatever.
Further ideas about t2t can be found in this article and others. Using staged computation, I can convert a non-trivial Scheme program to a Javascript program (a total of approximately 370 lines of repetitive grammar code, and, a total of approximately 260 lines of repetitive rewrite code spread across 4 major stages). I would do this for other target languages (like Python, WASM, etc.) but I don't have the time nor interest (volunteers welcome to pick my brain and to finish this work).
Revelations
We don't need other stuff, like fancy, over-kill data structures, to build text-to-text macro processors and transpilers. We need only one internal fancy data structure - the AST. String building and string interpolation and ASTs are enough. We don't even need to draw diagrams of ASTs, we can just use any BNF-like DSL syntax (YACC, Ohm, Antlr, etc.) to represent ASTs in 1D text form.
Compilers are just transpilers with the addition of linters for consistency checking and type checking. These linters are tools meant only for programmers. Users - non-programmers - don't care if strong type checking was used in the process of creating machine code for their apps. There is only one language for programming hardware - machine code. All higher-level programming languages just boil code down to machine code.
The meme that we must use programming languages and operating systems to create machine code apps is based on 1960s biases. In 2025, we are in a position to change these methods, if we wish. We can even use the current crop of text-based tools to incrementally change our methods and workflows over many years and keep programming the way we currently program in the mean time. For example, I have created examples of running machine code using diagrams as source code (DPLs instead of PLs) using Python and Javascript and bash. [Aside: this is easy and straight-forward to do using just our current technology and workflows]
See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com