

Continuing to think of a programming language based on text as being different from a programming language that uses a different syntax will result in construction of the wrong thing.
Programming is programming, not the act of drawing pretty pictures.
As far as I know, there are no decent visual programming editors and no non-textual syntaxes for programming. This is new ground. Researching existing "visual editors" will result in researching the wrong things.
The nearest I've seen to something in production is LabView. It fails to be reasonably useful because of the same failings that schematics have (see below).
Scratch is just more of the same. It is a visualization of textual programming. Nothing new. Not really a VPL. Scratch is like opcode mnemonics stretched over bit patterns and toggle switches controlled by character sequences. Scratch stretches pretty graphics over the sequential, synchronous programming paradigm
Programming is capable of being more than that. Especially programming for systems composed of many interconnected nodes, like what we're faced with today, e.g. internet, robotics, IoT, etc. Programming these kinds of things using islands of sequential code is like programming with opcodes in assembler. It works, but it isn't all that it could be.
In 1960, in-memory bit patterns arranged in a sequential manner, i.e. opcodes, was about all that existed. The English language was culled to find a few words that could be arranged neatly (using a pattern-matching technique called "parsing") to help in the act of building bit-code sequences. Words like “if”, “then”, “while”, etc.
Programming using a non-textual syntax is the same. We need to cull a few figures from the array of graphical possibilities and find a way to parse them to produce programs in a new-fangled assembler. An assembler that isn't synchronous, since synchrony defies asynchrony. Today’s problem space is asynchronous, not synchronous.
EE’s did something similar to this kind of culling, even before programming was invented. They came up with a pencil-and-paper notation for expressing otherwise complicated, massively parallel electronic devices - a notation called “schematics". EE's used figures that were of various shapes (rectangles, triangles, text, etc.) and lines (called “wires").
The problem with schematics is that they are not conceptually layered and do not invite the reader to gradually understand a design. Instead, schematics slam all of the details into the reader's face at once.
We need better notations to go beyond what our current notations are capable of. We see the inklings of what might be needed when we consider asynchronous programs and (the very few) asynchronous programming languages. Currently, the best that we can do is to manually construct solutions to asynchronous problems with our hands tied behind our backs by the constraints imposed by the Gutenberg text-only mindset.
The point of a good notation is to make concepts easier to reason about, not harder. Being able to express a concept in a notation is not as good as being easily able to express a concept.
Our current programming languages are mostly based on textual notations that are good for reasoning about single-threaded computations. Over decades of time, we’ve managed to graft multi-threading and asynchrony onto these notations, but, we could do better if we freed ourselves from thinking that programming is defined only by textual notation.
Noted physicist, Richard Feynman, broke away from text long enough to uncover deep secrets about an aspect of physics using diagrams that we now call “Feynman diagrams”.
Network developers draw pictures of networks, since words and existing textual programming languages fail them. You can translate drawings of networks into textual code, but, going this way - from text to pictures - is harder and restricts your thinking processes.
Normal humans - non-programmers - step up to whiteboards and naturally draw rectangles and ovals and lines and bits of text. What they draw tends to be understandable, but, could be more precise. What they draw is usually interpreted as closed figures that are completely isolated from one another. Current programming languages don’t give you complete isolation, hence, they defy normal intuition. Function calls cannot be easily drawn as arrows, since function calls imply control flow and sequencing along with data flow. Data flow languages provide full isolation, hence, can be considered to be the basis for futuristic programming notations.
A small number of programming languages, like Neva, FBP, Flyde, Misty, etc., are exploring the ideas of non-synchronous programming, but, most are still at the “assembler” level - giving programmers the bare necessities for manually building programs using asynchronous nodes. This is akin to using opcode mnemonics in the 1960s. Async programming is programming, but at a higher level than can be done with existing synchronous, sequential languages. Just like, in the early days, CPUs were just bits of electronics. You can do everything that a CPU can do with just a handful of transistors, but, the idea of CPUs gave us a new way to think about this stuff, i.e. a new “notation”. We need to jump the notational threshold in programming to think about async programming in richer ways.
We might be able to learn from the ideas of old-fashioned electronics schematics combined with the advances in synchronous PL design. For example, electronic circuits use the concept of “feedback”, but, existing PLs don’t make it easy to think this way and tend to obscure the whole issue by making it seem that “recursion” is the same as “feedback”. They’re not the same. Recursion is based on LIFO stacks, whereas feedback is based on FIFO stacks. You can build LIFO stacks using existing PLs, but that’s not the same as having a notation that has LIFO-ness built into it at the same level as having FIFO-ness (function calls) built into it. Thinking about programming in this way is akin to using handfuls of transistors instead of CPU I.C.s to build computers. It works, but it restricts your thinking.
Furthermore, electronic schematics employ massive parallelism. Schematics don’t make it easy enough to understand a design. Can we do better?
Visual programming languages are - visual. They use a non-textual, non-Gutenberg syntax. One can construct assemblers for such languages using textual techniques, but, those kinds of assemblers restrict our ability to reason about async problems in better ways. Using textual assemblers for these essentially-new concepts is a good idea, considering that most of our existing tools are textual in nature, e.g. CFG and PEG parsers. The fact that text is used to build assemblers doesn’t meant that the ultimate programming notation needs to be textual, too. For example, in my opinion, a network is better expressed as a bunch of boxes with lines between them, instead of as a bunch of textual lines with ASCII arrows between them.
This
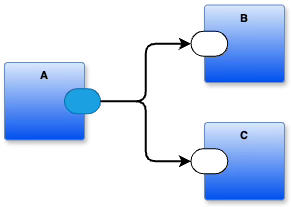
Is a better notation than
A -> B
A -> C
Or
A -> [B, C]
Or
A(B(...),C(...))
Or
A OUT1 -> IN B A OUT2 -> IN C
All of these notations express the same concept, but the rectangle and arrow notation makes it possible for me to imagine other combinations of drawings like
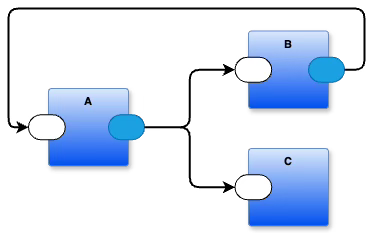
I would need to think hard about this if I wanted to write it as Gutenberg text (remember that feedback is not recursion). I’m sure that someone could show me how to write this in Gutenberg textual format, but, I still believe that they could not show me how to think and invent this using only Gutenberg textual format.
An example of feedback in actual use, is this WIP project (a Larson Scanner running in a browser):
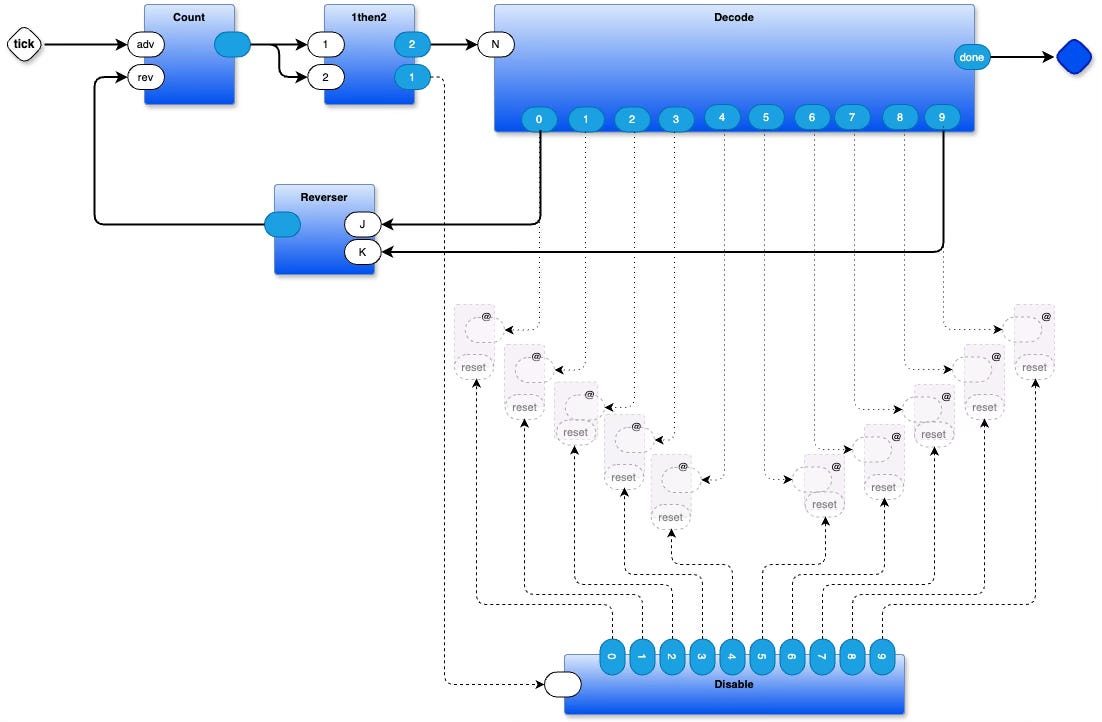
SVG
SVG is an example of textual syntax arranged in a non-Gutenberg manner.
Text, in SVG, is just another figure, like rectangles and ellipses.
SVG figures, unlike Gutenberg text, can be resized and can overlap.
PBP and 0D
I’ve been experimenting with something that I call PBP - Parts Based Programming. I also call it 0D (for zero-dependency, e.g. breaking inherent CALL/RETURN control flow dependencies).
An aspect of this experimentation is the idea of using existing diagram editors. I use draw.io. I’ve considered using Excalidraw and yEd, but historical momentum caused me to stick with draw.io.
In the 1960s, it was common to build languages and compilers in stages connected using syntax-directed translation.
This same technique, applied to today’s programming languages, makes it straight-forward to build new syntaxes for programming languages, without needing to entertain mega-projects like building graphical editors. The syntax-directed translation technique is even easier to use today than it was in the early days, thanks to PEG-based technologies like OhmJS and transpilation tools like t2t. The fact that OhmJS uses Javascript internally does not mean that it can only be used with Javascript. OhmJS is just a parsing technology which is language agnostic. I’ve used it with Python, Common Lisp and Odin code.
FP - Functional Programming
McCarthy invented a simple use of CPUs called Lisp 1.5. The initial version was created around 1958.
Lisp - early lisp - is a paradigm for functional programming. Functional programming does not allow mutation and is strongly LIFO-based. Extremely small, tight implementations of Lisp are possible, for example Tunney’s Sector Lisp (436 bytes).
The functional paradigm has been mutated and has grown into something that most popular programming languages are based upon today. The mutated version of functional programming involves type checking (a lint-ing technique to help developers reduce the number of bugs in their code) and violations of the spirit of pure functional programming, like mutable variables, heaps, bloatware, an emphasis on production engineering at the expense of DI and design freedom, etc.
McCarthy invented Lisp in the late 1950s. Some decades later, we re-discovered some of the basic tenets of FP, e.g. non-mutation, etc., but, we back-filled these ideas into PLs that are not FP at heart. The not-surprising result is bloatware.
Layering
One of the problems of many notations is the lack of layering coupled with isolated components.
An example of layering can be seen in the UNIX® shell.
In UNIX®, commands are fully decoupled through the use of processes. Processes encapsulate data and they, also, encapsulate control flow. In essence data flow languages and closures perform such full isolation, whereas functions in function-based languages do not do this.
Functions and OO objects encapsulate data, but, do not encapsulate control flow, since a function, or method, call transfers control from the caller to the callee.
Yet, full isolation is not enough. Further layering and structuring of isolated components is required. Some of the issues are discussed further in this article and some of the articles it references.
In the UNIX® shell, a textual concept, called a script composes commands into a sequence and redirects their inputs and outputs.
UNIX® processes contained the concept of multiple inputs and multiple outputs from the outset, but their use was restricted by the textual nature of the shell syntax. Furthermore, the concepts of fan-in and fan-out were not handled at a low level.
Today, with garbage collection, closures and queues, we can compose Parts better than the UNIX® shell can.
One way to incorporate layering into a flow-based notation, is to extend the notion of what a connection (“wire”) is.
To compose a little network of Parts, the container Part must pass data down to its sub-network, and forward data to its own outputs by accepting results passed up to it from its sub-network. Within the little network, Parts send data across to each other. Structuring wires in this way allows one to compose little networks using Leaf Parts and other Container Parts.
For completeness, we add a fourth direction - through - where data flows from the input of a Container directly to its own output. This turns out to be useful for stubbing Parts out in early design stages.
Connections - wires - can be considered as triples, not doubles
Direction [down, across, up, through]
Sender
Receiver.
See Also
Email: paultarvydas@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com