
Function Entanglement vs Structured Message Passing

Introduction
In this note, I discuss why a simple function call like f(x) produces unexpected - hidden - dependencies.
Functions (and methods) are entangled in ways that programmers take for granted and tend not to notice. This kind of entanglement impedes flexibility in software re-configuration and architecture.
I discuss a structured form of message passing that can augment programmers’ use of functions. These ideas are fleshed out in the 0D code repository, but, for purposes of this note, I will mostly use a simple, textual example.
Note, that the main thrust of this note is essentially psychological. The technology used is fairly trivial, but, a simple change in basic beliefs enables a more flexible way of thinking about software development.
Example
In the following, I show the problem of function entanglement by example.
The problem of entanglement exists in object-oriented code, also. Methods are functions. Methods do not implement message passing regardless of the terminology used. I regard message passing to be an asynchronous, non-blocking operation. Functions block. Methods, also, block. Functions operate in a synchronous manner. Methods, also, operate in a synchronous manner.
The fundamental problem of entanglement is that knowledge about the callee is hard-wired into the caller’s code. The caller’s code can not be used in other applications without dragging the callee’s code along into the other applications.
As a simple example, I imagine developing two applications that share some common code.
I begin with app1.
The application uses two apparently distinct units of software, unitA and unitB. A unit is just a grouping of related software, such as a file, a group of files, a sub-directory containing code files, an object, etc.
UnitA implements some code. Let’s call the code h() a so-called “function”.
UnitB, also, implements some code. Somewhere in UnitB’s code is another function. Let’s call it f().
Function h() in unitA calls f() in unitB.
function h (...) {
f (42);
}or in OO terms,
method h (... obj ...) {
obj.f (42);
}Now, I want to create another application - app2.
App2 re-uses unitA, but, uses a different block of code, unitC instead of unitB. I want to provide the same data from h() to a function in unitC. UnitC, though does not implement a function called f(). UnitC, though, does implement a function called g() which takes the same parameter(s) as f(), but does something different with the data.
Using our current programming workflow and tools, I end up needing to hack on the code for h() to change it to be:
function h (...) {
g (42);
}or, in OO terms
method h (... obj ...) {
obj.g (42);
}I can't treat unitA as a black box and just simply use it in the new application. I have to open up the source code and modify it.
The caller needs to know that the callee has a method/function with a specific name - f.
In Appendix 1, I provide runnable example code written in Python that demonstrates this problem and fails due to the problem of entanglement.
Unix solved this problem with I/O redirection. Unix remaps output "names" to input "names". A really common remapping is that of mapping the name stdout to the name stdin. This is what the pipe operator (|) does. In fact, Unix doesn't actually remap names, it remaps connections (which it calls "pipes").
Structured Message Passing and Structured Concurrency
One way to solve the problem of entanglement is by using structured message passing which re-maps messages, instead of using function calling. Furthermore, structured message passing enables the use of layers and component abstraction in software programming.
Goals of Structured Message Passing
Flexibility, re-use and multiple-use.
Isolation: encapsulation of data and encapsulation of control flow
Stand-alone testability without the need for stubbing external code out.
Layering of designs, expressing design intent (DI) while reducing information overload and increasing understandability of code.
Flexibility With Structured Message Passing
A similar solution, based on structured message passing, to the above code might be to write1:
function h (...) {
send ('f', 42)
}or, in OO,
method h (...) {
self.send ('f', 42)
}Which says, put the value 42 onto unitA's own output queue with the tag 'f'. I.E. create a message, which is a 2-tuple {'f', 42}.
Something else remaps the message to become {'g', 42} as the message is transferred from unitA’s output queue to the input queue of some component in the 2nd project.
In Unix, the remapping is done by Unix's internal process dispatcher. This involves a complicated series of low-level operations that involve open()ing the output side of a pipe and open()ing the input side of the same pipe.
To further encourage use of message-passing as well as function-calling, we could use a new syntax that makes message-passing appear to be as easily available as function-calling. Maybe something like...
function h (...) {
f⟪42⟫
}or, in OO
method h (...) {
self.f⟪42⟫
}[N.B. This example syntax uses Unicode brackets ⟪...⟫ in order to avoid further overloading of the already-overloaded ASCII character set].
In Appendix 2, I provide runnable example code written in Python. The code runs and succeeds, unlike the function-based code in previous sections.
Layering and Nesting
From a Lisp-y perspective, Unix-style remapping is single-level and atomic, and, is not recursively-defined like lisp lists. There is only one dispatcher in Unix. To get multiple layers of this behaviour, we need to create bash scripts that call other bash scripts, etc.
I implement recursively-defined dispatchers. This is not hard to imagine if one uses closures with FIFO queues, etc., instead of using big wads of operating system code written in C, or, assembler, or any other function-based programming language.
I implement 2 kinds of components:
1. code components, called "Leaf" components
2. dispatcher components that encapsulate a scope, called "Container" components
I specify connections as mappings {'f', ???} -> {'g', ???}. [There's more to this. I'm trying to simplify. Connections in nestable components actually need to be triples.].
Containers are scoped and encapsulated and isolated in that they can only route messages between their directly-owned children (and themselves).
These ideas have been realized in programming languages like Odin, Python and Crystal. Higher-level meta-language and JS versions are WIP2 3.
Software components (SWBs - SoftWare Blocks) can use functions and methods internally, but, must use FIFO-based structured message sending for external communication. SWBs cannot directly send messages to other SWBs. SWBs cannot call functions and methods in other SWBs, they can only call functions and methods that are enclosed in their own scope. The only thing that SWBs can do is deal with incoming messages and produce outgoing messages. A SWB has no idea of where a message originated nor where an output will end up going to. In fact, an output might go to more than one port, but, this is determined by the enclosing Container component, not the code inside the SWB.
Drawware
A benefit of dividing programs up like this is that you can invent sensible DPLs (Diagrammatic Programming Languages) due mostly to the full isolation of information within components - not just data encapsulation, but, also, control flow isolation. I use a visual syntax to represent components with ports (input and output ports) for expressing architecture and message flows. Currently, for lack of other tools, I use draw.io as a program editor.
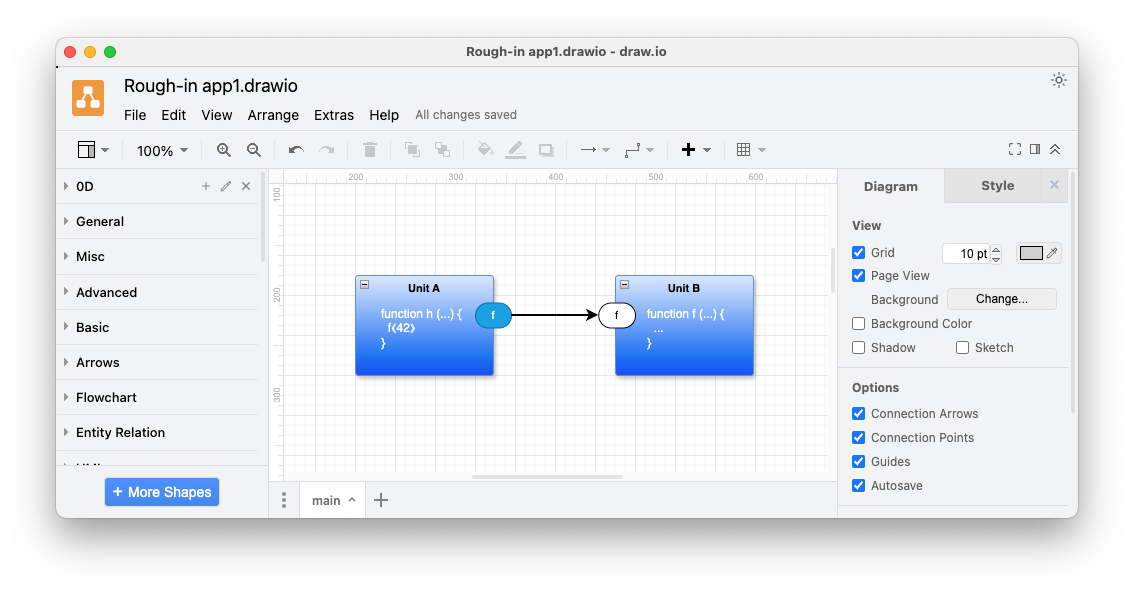
Fig. 1 A.f connected to B.F
[N.B. again, this very simplified example accomplishes nothing in practice, and, is used only for the expository purposes of this note. At present, I don’t write the code (the white text of functions h and f) on the diagram itself, but make it available to a text editor that edits the insides of components4].
The diagram looks like a common “node and arrow” diagram, except that components are represented as rectangles with named ports on them. Arrows can only make connections between ports. Arrows cannot cross rectangle boundaries. Components may contain other little networks of components, recursively.
One of the key flavours of secret sauce for implementing structured message passing is the idea of using a single input queue for each component, instead of allowing one queue per port. Output queues are constrained in a similar manner, i.e. one output queue per component.
For this simplified example, I’ve drawn the code for unitB/f() directly onto the component. In general, component B might contain inner little networks which get input from B’s “f” port. We can’t tell how B is implemented nor what’s going on inside of B simply by looking at a diagram. The details of B are usually elided - abstracted. B might contain 10s of components with a total of some 100s of ports, but, we can see only the one port on this diagram - all inner ports feed in to and out of B’s ports. Alternately, B might be implemented as a Leaf component, containing only code and no more ports. We simply can’t know (nor care) at this layer, what’s inside of A nor B.
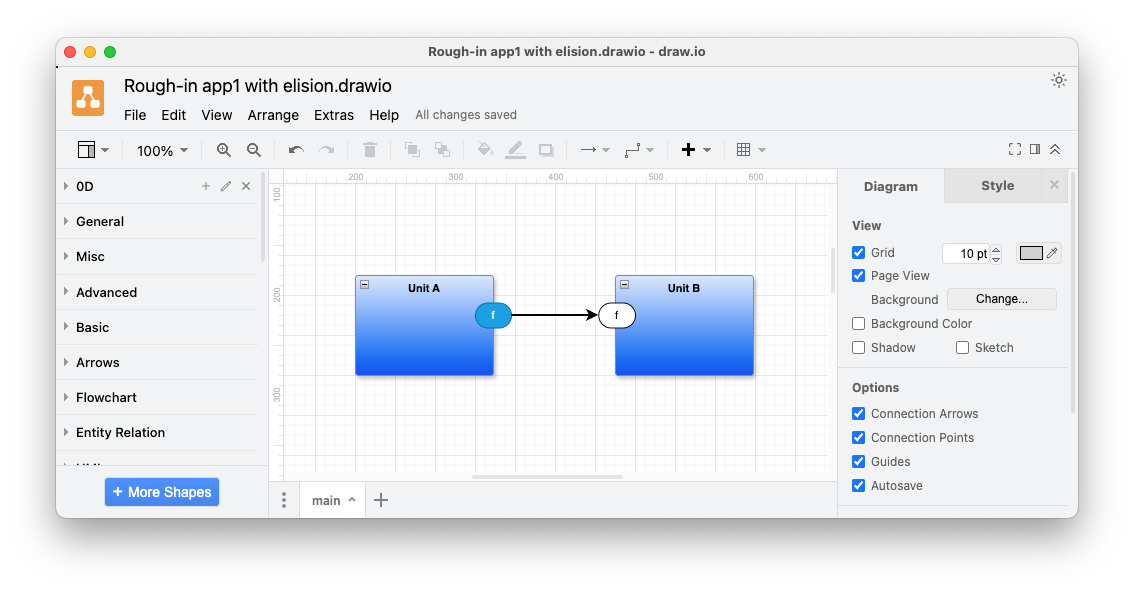
Fig. 2 Eliding Component Implementations
Ports are unidirectional - strictly input or output. As drawn, this diagram says that B has no output ports. Maybe B might represents a Unix daemon or some kind of logger that scribbles data onto some kind of internal database which is not shown at this layer of the diagram.
Fan-out is allowed - one port can feed multiple ports.
Fan-in is allowed - many ports can feed a single input port.
Feedback loops are allowed - arrows can loop from a component’s output port back to its own input port. Note that a feedback loop based on FIFO queues and message passing has different semantics than a feedback loop in a function-based (LIFO callstack based) paradigm. Using FIFOs, messages go to the end of the line and have to wait their turn, while in a function-based paradigm, feedback CALLs (aka “recursion”) jump to the front of the line and are processed immediately.
There is one input queue per component - not one input queue per port. This restriction makes abstraction easier to express, and, it preserves the time-ordered relationships between messages, e.g. allowing code to determine order of arrival of messages, like “message X arrived on port P before message Y arrived on port Q”. Preserving this information is necessary for building sequencers5. A simplifying assumption of the function-based paradigm is that this kind of time-related information is unimportant and, therefore, can be omitted from the function-based notation itself. You can preserve this information in the function-based paradigm, but, you must do so explicitly - it is not a first-class entity within the notation itself with well-defined, built-in semantics.
The equivalent of FP’s “referential transparency” is provided by simple consideration of port-compatibility. A component can replace another component as long as it has the same set6 of ports. There are fewer restrictions on referential transparency in the structured message sending paradigm than in the function-based paradigm. SWBs with multiple ports can replace compatible SWBs with similar multiple ports, whereas in the function-based paradigm, replaceable functions must have exactly one7 input parameter of compatible type and one output parameter of compatible type and must discard time-ordering information.
Type checking can be performed using components. Ports do not need to be statically typed. Type checking can be optimized to work ahead of time, but, also, type checking can be done incrementally and in a sequentially filtered - layered - manner. Non-static type checking can be equated to input validation in GUIs as we currently know them.
Fig. 1 represents one project. A second project might be written as:
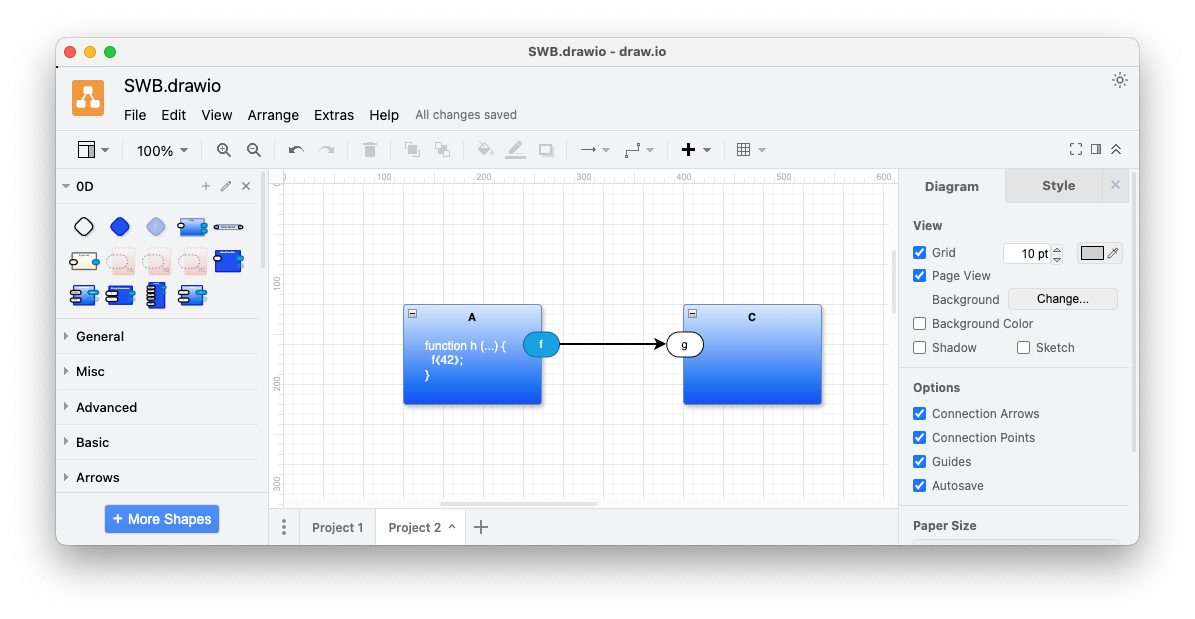
Fig. 3 A.f connected to C.g
Where component B is replaced by component C.
Note that, in this case, A’s f output can be successfully sent to C’s g input without modifying A’s internal code.
Flexibility
Isolation makes it possible to shuffle and change architectures by rewiring components.
Isolation makes it possible use components across multiple projects (multiple-use, not just re-use8).
Stand-Alone Testing
Isolation makes it possible to use a hardware-like testing attitude: stimulate inputs, observe outputs.
Isolation and structured use of ports make it unnecessary to drag other components along into a test jig. External components do not need to be stubbed out solely for purposes of testing.
Components can be tested in a stand-alone manner, one by one.
Out-Sourcing Component Implementation
Specifying components by input/output behaviour based on structured use of ports makes it possible to out-source implementation of components and makes incoming inspection easier.
Easier testing of components on a go/no-go basis makes it possible perform acceptance testing and Incoming inspection of outsourced components.
Appendix 1 - Function Entanglement
The following code is written in the Python programming language in the usual function-based style.
class A:
def run (self, obj):
obj.f (42)
class B:
def f (self, n):
print (f"object B: f got {n}")
class C:
def g (self, n):
print (f"object C: g got {n}")
class Project1:
def __init__ (self):
objA = A ()
objB = B ()
objA.run (objB)
class Project2:
def __init__ (self):
objA = A ()
objC = C ()
objA.run (objC)
Project1 ()
Project2 ()This code is available for download in the git repository https://github.com/guitarvydas/swb.
Use the command
make function_basedto run the above code without downloading the repository and to see the failure, save the code into a file function_based.py, and use the command-line command:
python3 function_based.pyThis code runs, but, fails in the end. It succeeds for App1 which calls f() in class unitB but fails in App2 which attempts to call a non-existent f() in class unitC.
Appendix 2 - Structured Message Passing
The following code is written in the Python programming language. Python does not directly support structured message passing. I use Python as a kind of assembly language for structured message passing. This code seems to require more lines of code than the above function-based code, but, that is because Python does not directly support structured message passing. The size of the code could be greatly reduced by supplying one or more syntactic skins that express structured message passing more succinctly.
class Queue:
def __init__ (self):
self.q = []
def append (self, message):
self.q.insert (0, message)
def empty (self):
return 0 == len (self.q)
def dequeue (self):
return self.q.pop ()
class A:
def __init__ (self):
self.outq = Queue ()
def run (self):
self.send ("f", 42)
def send (self, id, val):
self.outq.append ({"port" : id, "data": val})
class B:
def __init__ (self):
self.inq = []
def subr_f (self, n):
print (f"component B: f got {n}")
def handler (self, message):
self.subr_f (message ["data"])
class C:
def __init__ (self):
self.inq = []
def subr_g (self, n):
print (f"component C: g got {n}")
def handler (self, message):
self.subr_g (message ["data"])
def remapMessage (message, destinationPort):
return { "port": destinationPort, "data": message ["data"] }
class App1:
def __init__ (self):
cA = A ()
cB = B ()
cA.run ()
msg = remapMessage (cA.outq.dequeue (), "f")
cB.handler (msg)
class App2:
def __init__ (self):
cA = A ()
cC = C ()
cA.run ()
msg = remapMessage (cA.outq.dequeue (), "g")
cC.handler (msg)
App1 ()
App2 ()This code is available for download in the git repository https://github.com/guitarvydas/swb/tree/main/implementation.
Use the command
make message_basedto run the above code without downloading the repository and to see it work successfully. Save the code into a file message_based.py, and use the command-line command:
python3 message_based.pyThis code runs successfully in both cases. UnitA passes information to B’s f() and passes information to C’s g().
Note, also, that the above code elides many details required for practical use of this technique. For example, the above code does not implement Container components, nor generalized connection tables, nor error handling. Eliding these details allows for simpler exposition of many of the fundamental ideas involved. The technology involved is quite simple and can be implemented by any competent programmer. The main thrust of the structured message passing idea is mostly psychological - the idea enables new ways to structure programs and enables true asynchronous concurrent operation and solves the function entanglement problem.
A more complete implementation can be found in Appendix 3.
Appendix 3 - Practical Implementation Using A DPL
In a working implementation of the toy examples used in this essay, we add
A top level Container that represents the application. In this case the Container is shown on the tab ‘main’ of the diagram.
A top level input port for the application
An input port for unitA, that is fed from the top level input port
Error output ports for unitA, unitB and the top level application. For now, the error output ports of unitA and unitB are tied together and feed into the top level error port.
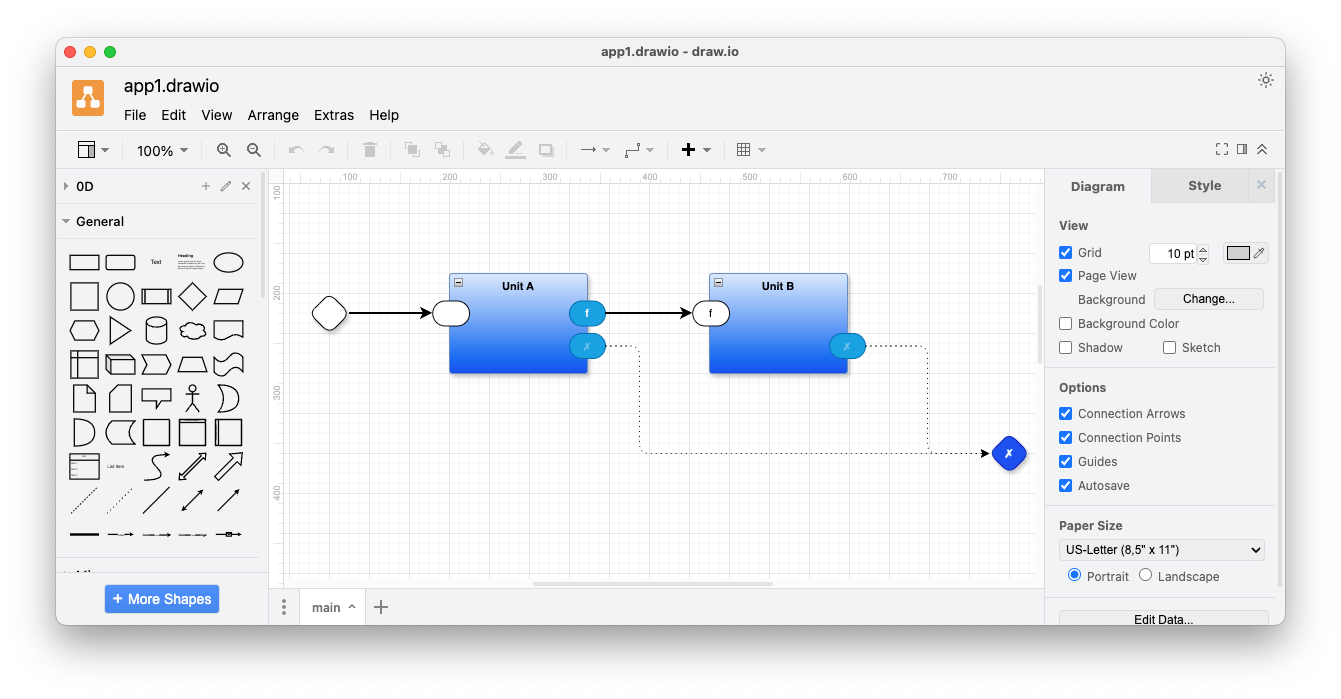
Fig. 4 Implementation of app1.
A Makefile. Use ‘make’ to run the code.
A file ‘main1.py’ that defines the Leaf components used in app1 - unitA.py and unitB.py - and starts up the system by calling ‘zd.initialize ()’ and ‘zd.start (...)’
Likewise for app2, we use a similar diagram and ‘main2.py’. The diagram in Fig. 4 is different from that of Fig. 3 in that the component unitC is used in place of component unitB.
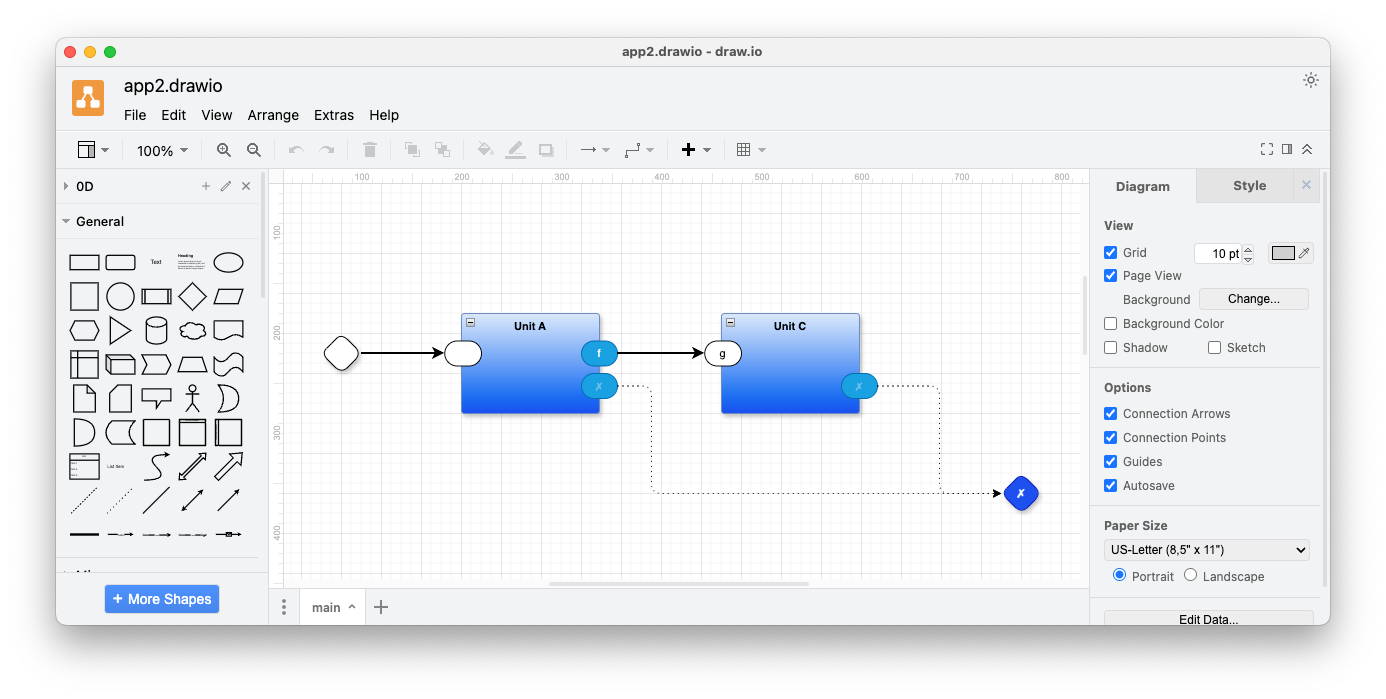
Fig. 5 Implementation of app2.
The Makefile compiles fig. 3 to a JSON file called app1.drawio.json.
The Makefile compiles fig. 4 to a JSON file called app2.drawio.json.
The Makefile runs both apps. The resulting output is:
Application 1
B got 42 on port f
Application 2
C got 42 on port gThis toy example shows that component unitA is used in both applications - app1 and app2 - but feeds two different components - unitB and unitC - with the same data.
This demonstrates that we can simply use unitA multiple times in different applications without needing to tweak unitA’s code. UnitA is a “black box” - we don’t need to know anything about the internals of unitA, we simply include it in both projects.
Larger, more interesting projects using 0D have been built, for example text to text transpilers, but, these projects include details that tend to obscure the simple techniques for avoiding function entanglement. It was thought better to use the above simple, but useless, examples for this essay than real-life uses of 0D.
Future WIP
Leaf and Container Components
Currently, it is straight forward to include Leaf components in projects using Python syntax.
We can, also, include Container components in projects by transpiling them to JSON, then adding the JSON files to the command line in the Makefile. The last argument in the line
@python3 main1.py . 0D/python "" main app1.drawio.jsonis shown as app1.drawio.json, but, is in reality, a list of .json files.
We have yet to determine how to include Container components that use Leaf components in a nested manner. Currently, all Leaf components must be included in the mainline for each project, which means that we need to know which Leaf components are needed by every Container component used in the project. At this point, this is not an impediment in the workflow, but, we anticipate that it will become an issue as projects scale upward in size and include many Containers.
0D Repository
Currently, the 0D repository contains the Python kernel and an earlier version of the 0D kernel written in the Odin programming language. The repository also contains some 15 simple examples of 0D usage.
The repository also contains the diagram transpiler which converts diagrams from draw.io format to JSON format. Currently, the transpiler is written in the Odin language and uses an XML parser.
It is planned to convert the 0D repository to contain only the Python kernel, as a single file, as is done in the sample code for this essay.
It is planned to move all examples of 0D usage into a separate directory, and, to convert their main.py files to the more succinct form used in this essay.
It is planned to rewrite the diagram transpiler using the t2t command-line tool, using text-to-text conversion instead of using a third-party XML parser library.
Progress on all of these fronts is slow due to unrelated time pressures. Help or collaboration would be appreciated.
References
0D (zero dependency - component based programming including drawware): https://github.com/guitarvydas/0D
Draw.io: https://app.diagrams.net
CALL/RETURN Spaghetti (an essay about using message-passing for asynchronous concurrency and DPLs): https://guitarvydas.github.io/2020/12/09/CALL-RETURN-Spaghetti.html
See Also
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: https://guitarvydas.github.io/
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/Jjx62ypR
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: https://tarvydas.gumroad.com
Twitter: @paul_tarvydas
Github repositories: https://github.com/guitarvydas
Note that this is not real code. The code is stylized for expository purposes. It is straight-forward to transliterate this code into legal code for most programming languages.
Work In Progress
Help and collaborators welcome.
At present, the insides of components are edited using draw.io and/or programmers’ text editors, for Container (little networks) and Leaf (code) components respectively. One could imagine other kinds of editors, like Statecharts and Drakon and Subtext, for other kinds of insides.
Physics informs us that there is actually only one kind of “race condition” - did two events arrive “at the same time?”. We can deal with this kind of race condition by using faster hardware or by building state machines with overrun detection. All other kinds of “race conditions” are self-inflicted through inappropriate choice of notation. This includes the plethora of edge cases called “race conditions” in software development.
I probably mean “superset”?. In practice, though, this issue has not come up, it seems that having exactly the same set of ports is “good enough”. “Good enough” means “practical”. Consideration for issues of total robustness can be relegated to linters instead of inflicting changes on the notations to handle each and every rare edge case, and, to production engineering concerns, when design layering and isolation are properly employed.
Currying says that functions devolve into functions of single parameters. This is borne out by the fact that “functions” are typically implemented by passing single blocks of data on the callstack, which can be further broken down using destructuring. Passing data in separate registers is a form of premature optimization of destructuring.
https://www.amazon.com/Framing-Software-Reuse-Lessons-World/dp/013327859X. Paul Bassett describes a kind of macro language that is used to transform source code into new source code tailored for a specific purpose. His work was/is used in production in a Fortune 50 company. He stresses, multiple-use instead of class-based re-use. I do something related in concept using t2t (text-to-text) technology that employs PEG parsing. PEG hadn’t been formalized yet when Bassett published the book.