
Building Software Using Black Boxes
Structured Asynchronous Message Passing 2024-11-19

Goal
The goal is to allow technical and non-technical users to snap Software Bricks - ė components - together to form new solutions to problems and to form new devices and products.
Ė is pronounced “eh?” (or “A”) in Canadian English and is spelled “eh” in ASCII. Ė is a letter in the Lithuanian alphabet.
In a sense, ė is like λ, but, different.
We want software development to be similar to using the children’s toy LEGO®.
What does it take to make snap-able software components? Why are current programming techniques, based on functions and λs not good enough?
ė Teaser
In the following short video snippet taken from a longer video, you can see a very simple drawware system being used.
Note that I build a concurrent, parallel system using fan-out and fan-in using simple copy and paste. It is so simple that I don’t even bother to mention that this involves concurrency.
Concepts like asynchronous concurrency and fan-out are hard to express in current programming languages, like Rust, Python, etc. Yet, this teaser shows how to express these concepts in a very simple manner.
It is unnatural to share memory in modern networks of distributed machines, like the internet, robots, IoT, blockchain, etc. The fact that the components in this teaser video are completely stand-alone, and, don’t share memory, means that even a notation as simple as this one models modern hardware “better” than existing programming languages like Rust, Python, etc.
Composition - Snapping Components Together
Software components must be treated as “black boxes”. Users - developers and non-developers - only need to know what components are available and what their input and output ports are.
Users do not need to know what is inside of most software components.
In fact, users, cannot know what is inside of ė components.
Users need to select existing ė components and users need to connect them up in various ways.
Users need to change the wiring between ė components in a flexible way to create new software architectures and solutions.
An obvious way to express ė components is as rectangles with input and output ports, on diagrams. Connections can be represented as arrows. Arrows do not go from rectangle to rectangle, but from port to port, never crossing component boundaries.
Layering
Users need to create software architectures in an iterative manner.
Users need to “grow” architectures as they learn new information about the target problem domain.
When incrementally-built architectures grow beyond a certain size[1], users need to lasso portions of the architectures and to replace the lassoed portions by single abstractions that move the lassoed details into other layers. The detailed information must not be lost, it must simply be elided and moved over into other layers of detail.
Users - technical and non-technical - must never be overwhelmed by walls of detail. Details must be layered in bite-sized pieces. Users can “drill down” into more detailed layers as desired.
Current programming languages and paradigms, e.g. Rust, Haskell, Python, etc., defy hierarchical layering, and, cause programs to act like Swiss watches whose operations are intricately coupled using 100’s of little gears all running in lock-step. When one tooth breaks off of one gear, the whole device stops working, There are no buffers - no “clutches” between gear assemblies. Similarly, current-day programmers are forced to expand software details in a breadth-first manner, creating vast, infinite canvases of functions, instead of using many hierarchical layers with “clutches” in between the components. Namespaces help ameliorate the over-use of text-based notations, but, are simply bandaids glued into textual, synchronous, function-based representations of tightly-coupled details. Due to tight coupling, software cannot be easily scaled upwards and subsections of programs cannot be easily extracted and dropped into different applications.
Successful layered abstraction is achieved by replacing a group of ė components with single ė components with the same number of ports, or - ideally - a fewer number of ports.
This means that arrows cannot cross the boundaries of ė components. Arrows must terminate at ports. Arrows must emanate from ports. Black boxes remain opaque. Arrows can feed into input ports of black boxes and arrows can source out of output ports of black boxes, but, arrows can’t pierce through the walls of black boxes.
The Secret Sauce of SAMP
Layering is the “secret sauce” of structured, asynchronous message passing.
Asynchronous layering is difficult to even imagine when using only a synchronous paradigm, yet, it is easy to implement using existing programming languages.
A classic example of layering is the OSI 7 Layer model. The model makes sense, but, defies straight-forward implementation using function-based, synchronous programming languages. Synchronous programming languages require the use of context-switching engines which tend to slow down, tightly couple and complicate implementations of the OSI 7 Layer model. Shifting one’s thinking to closures with queues (FIFO, not LIFO) makes it, suddenly, straight-forward to realize the layered model. We already have the technology to accomplish this, we simply need to change our mindset.
Most humans already use layering in day-to-day life. For example, in business, layered organizations are defined by ORG charts. Upper layers - upper management - never become overwhelmed with detail. They punt detail down to sub departments. Implicit rules, like “no going over the boss’ head” and “no micromanagement” keep the structures layered, isolated and operating successfully. With structured asynchronous message passing, we can build software systems in similar ways.
Describing Black Boxes
How do you describe black boxes in a way that makes them usable and makes it possible to use black boxes to compose solutions to problems?
Following are some suggestions based on experience and experiments ...
Closed, Opaque
A black box is a closed unit. Maybe it’s a rectangle figure on a diagram. Maybe it’s a cube in a 3D editor, like Blender[2], or a spreadsheet with well-defined inputs and well-defined outputs.
Black boxes are opaque. You cannot see what is inside a black box. Does it contain beautifully structured code, or, are the innards a mess of global variables and ad-hoc mutation? You can’t know. You don’t care as long as the black box lives up to its guarantees.
Ports
A black box has input ports. You can send data into black boxes by sending messages containing data, asynchronously, one-way, into a black box’s input ports. Note that messages can be trickled into input ports over time - there is no need to send all data at once. Timing and ordering are elements of input handling. It is not particularly difficult to express timing relationships in programs. Statecharts[3] provide one way to deal with such trickles of data. Drakon[4] might be another way to deal with such trickles.
A black box has output ports. A black box can create output messages and plunk them into its own output ports, in the order that the output messages were generated ,,, but, a black box cannot decide on the final targets for these output messages. The decision for routing messages between black boxes is the sole responsibility of upper layers - immediate parent Container components (which are black boxes, also). Timing and ordering are elements of output generation.
Black boxes can have multiple inputs and multiple outputs. Black boxes are not restricted to single inputs and single outputs like functions are1.
Guarantees and Undefined Behaviour
Guarantees. Black boxes provide guarantees with respect to how they will react to certain data coming in on input ports, or, combinations of such data.
Undefined behaviour. Some sequences of inputs will produce guaranteed results. Other, out-of-bounds inputs will result in undefined behaviour.
Containers and Leaves
There are two kinds of black-box components:
Leaf components, and,
Container components.
Containers contain mixtures of components
Containers are “recursively defined”, whereas Leaf components work as one-shot actions. Containers are like little networks. Leaf components contain “code” written in some “programming language”.
Connections, Wiring
Components wire up black boxes, and, can re-wire everything at will. Re-wiring should not happen at run-time, since that would constitue dynamic behaviour, such as self-modifying code. We all know that dynamic behaviour is hard to debug. Re-wiring, and multiple use of components, before runtime, improves flexibility. You can change your mind and quickly re-wire the little networks, without having to re-implement and re-visit work that you’ve already done in implementing the code / little-networks in nodes you already have on-hand. This fosters a “build and forget” attitude.
Container components are constructed by connecting output ports of components to input ports of other components.
Connection Directions
There are four fundamental ways to connect components:
“Down” - connect Container inputs to inputs of children contained in the Container.
“Across” - connect outputs of children to inputs of other children within the same Container. No component may connect to ports outside of its own container - not upwards, not sideways, not downwards to grandchildren.
“Up” - connect children outputs to outputs of their enclosing Container.
“Through” - connect inputs of Containers to outputs of the same Container. This supports “stubbing out” the implementation of components.
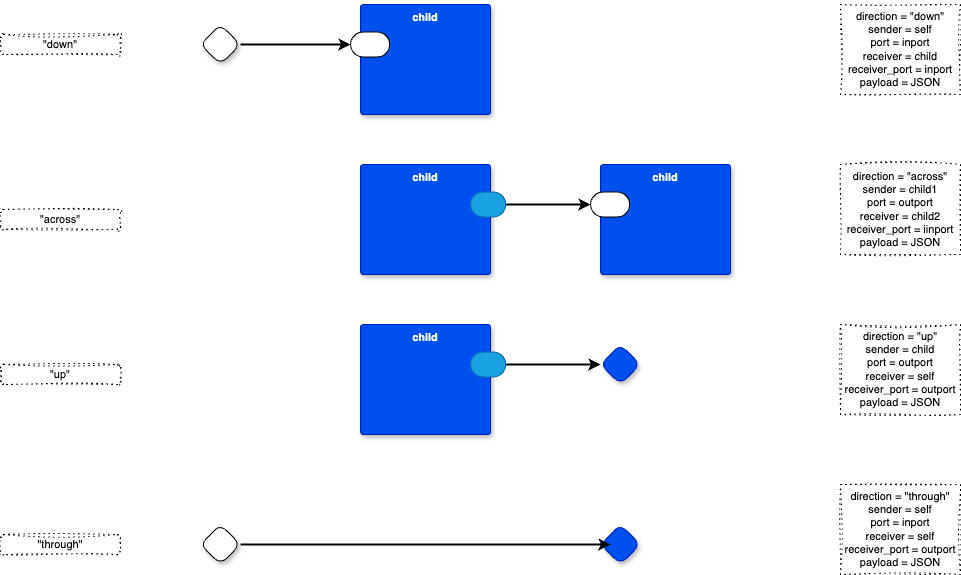
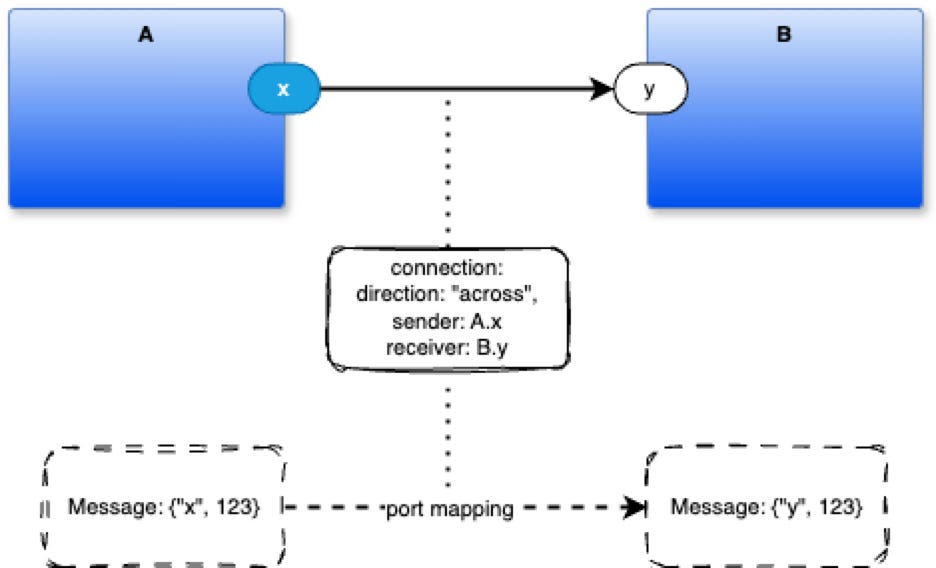
Connections Are Triples, Not Doubles
Direction (“down”, “across”, “up”, “through”)
Sender. Described by a pair: the sender component and its port name.
Receiver. Described by a pair: the receiver component and its port name.
Atomicity
All connections within a single Container must be processed, during routing, atomically.
This prevents other messages from sneaking in and upsetting the relative time-ordering of messages.
Atomicity is easy to accomplish when implementing SAMP inside of function-based operating systems. Functions containing for-loops are processed atomically by default in such systems.
Atomicity only becomes an issue when SAMP is implemented on bare hardware - i.e. without requiring the use of context-switching operating systems. In such cases, atomicity is well understood and documented in EE hardware design (search for “NMI” and “IRQ” techniques).
Rewiring
Little networks - Containers - can be re-wired simply by deleting connections and creating new connections between components.
In drawing editors, this consists of selecting specific arrows and deleting them. Then, adding new arrows to the drawings.
Namespaces
The namespaces of components are completely private to the components. Components can only expose their ports. Port names do not clash with port names of other components, because connections are triples, not doubles. When a message is routed from one port to another, the port names are adjusted to suit the names used by the receiver.
Abstraction
We must never overwhelm users with too much detail, while still expressing the full amount of detail needed to solve the problem.
Clusters of little networks can be lassoed and replaced by single components, moving the lassoed portions into other little networks that contain the actual elided details. To accomplish this, one creates a selection boundary around a cluster of components and replaces all points where connections cross the boundary with new ports (“gates”). Note that this is directly related to the concepts of scalability. To accomplish this kind of HCI, a notation must support fan-in and fan-out. Fan-in means that multiple output ports can feed data into a single input port. Fan-out means that a single output port can feed multiple input ports. Asynchronous fan-out is typically prohibited in conventional function-based programming languages.
As an example of layered abstraction, the following little network ...

Might be rewritten as ...


Creating little networks using structured, asynchronous message passing, is fairly easy using common programming languages. Programmers only need to know how to make classes for queues and how to create closures or anonymous functions. All of these techniques are supported, trivially, in modern programming languages. The largest difficulty in employing these techniques, is only that of changing one’s mental perspective, rather than actual difficulty caused by technological considerations.
Queue Per Component, Not Queue Per Port
Each component has exactly 1 input queue, and, 1 output queue.
Messages are fully processed in order of arrival, one at a time.
The concept of “processing” a message is chopped up into smaller chunks than is traditionally done in function-based programming, hence, this is quite manageable and succinct in practice.
The concept of async / await in modern programming languages is very similar in intent to the chopping-up meme, above. Textual syntax for this kind of thing just obfuscates what is really going on. It makes more sense when laid out with a DPL syntax. If you already know how to use async/await, then you already know how to “process” a message in small, asynchronous steps.
Hidden Dependencies Which Must Be Avoided
Snapping software bricks together like in the children's toy LEGO® requires that we avoid common - usually overlooked - kinds of dependencies that are embedded in popular programming languages and operating systems:
Naming. Components cannot call functions in other components and cannot directly name ports of other components. Only direct-parent Containers get the privilege of routing messages between their children. Children components cannot hard-wire names of external functions nor external ports into their code. Components cannot import names from other components, not port names, not function names. An exception to the previous sentence is that Containers can refer to their own port names and port names of their immediate children, but, cannot look “inside” of their children. Containers connect ports to other ports by mapping port names, as shown above.
Routing. Side effects are OK as long as they are managed in a structured manner. Components can produce many output messages in reaction to single input messages. Their direct parent Containers can route these messages to other components - to themselves or to their direct children. In contrast, Functional Programming restricts combination of functions in only one way. Pure FP prohibits side effects. In FP, callees must always route return messages to their callers. Callers must only send one message to callees, albeit the message can contain data that can be destructured to appear as many separate pieces of information. Callees must only return one message to callers, and, they must return a message to their callers.
Blocking. Sending a message must not block a component. A message-send is a one-way operation and does not pause the component to wait for a reply. In contrast, function-based programming uses functions which imply blocking and pausing execution of the caller until some value is returned by the callee. In function-based programming, it is impossible to know how deep the blocking goes - a callee may call another function and block waiting for a returned value. It is possible to break functions down into multiple functions, adding an unknown number of pauses in call chains. When writing “code”, one cannot know how deep blocking will be when any function is called. The number of blockages might change depending on the whims of downstream function creators. The upstream programmer has no easy way of knowing what the ultimate blocking-related result will be. Text-based band-aids, like async and await, have been invented, but cause cognitive overloading for expressing such a simple concept as one-way, asynchronous message sending.
Drawings to XML
Many existing drawing editors save drawings as text in XML format.
I use the draw.io[5] editor which saves its drawings in graphML[6] format - basically a variant of XML.
We already have lots of tools - like complier-compilers and PEG[7] parsers - that can parse text. These tools are well-suited to ingesting XML and for producing executable code from the XML.
Currently I use a small program called das2json[8] to inhale graphML and to exhale pared-down JSON[9]. The JSON data is used by a 0D[8] kernel to execute the drawing. Das2json is currently written in the Odin[10] programming language and the current version of the 0D kernel uses the Python language[11] and Leaf components written in Python.
I plan to use t2t[12], based on OhmJS[13], and jq[14] to re-implement das2json. I plan to re-implement a yet-further-simplified version of the 0D kernel using Python coroutine primitives (async and await).
XML to JSON
The following video snippet, from a longer video shows what .drawio files look like and how they can be culled down to contain only semantically-interesting information, by discarding graphical information.
Full videos
The above video snippets were extracted from longer videos. The goal of these full videos is to show progress on building an experimental REPL - Read Eval Print Loop - using a blunderbuss approach on modern hardware. It turns out that, for the purpose of helping developers develop programs using modern development hardware, low-level efficiency is not a great concern. Blunderbuss use of what used to be considered heavy-weight techniques, such as operating system processes, is “good enough”.
Many of these videos have been previously published on my YouTube and Substack channels.
The following video, previously unpublished, discusses an article that I posted to substack https://programmingsimplicity.substack.com/p/building-a-repl-in-2024?r=1egdky which discusses the results of the REPL experimentation, above.
FoC demo
My goal, in general, is to upgrade DX - Developer eXperience - instead of concentrating solely on upgrading UX - User eXperience. The hope is that by providing better tools, we can remove cognitive load for developers, allowing developers to be more inventive, and to create better UX tools for non-developers.
To this end, I gave a short (7 minute) demo to the FoC - Future of Computing - group on June 26, 2024. The following is a recording of the canned demo.
Acknowledgements
Zac Nowicki was instrumental in bringing das2json and 0D to life by building early versions of both in Odin. I ported the Odin 0D kernel to Python using Zac’s code as a guideline.
I’ve received many comments that have shaped my thoughts from people like Rajiv Abraham, Ken Kan, Steve Phillips, Boken Lin, Ken Deaton, Ric Holt, James Cordy, Jos’h Fuller, Ed Katz, and many, many others on the programming simplicity and FBP Discord groups and the FoC slack group.
Bibliography
[1] Rule of 7 from https://guitarvydas.github.io/2023/04/03/Rule-of-7.html]
[2] Blender from https://www.blender.org
[3] Statecharts from https://guitarvydas.github.io/2023/11/27/Statecharts-Papers-We-Love-Video.html
[4] Drakon from https://drakon-editor.sourceforge.net
[5] Draw.io from https://app.diagrams.net
[6] GraphML from http://graphml.graphdrawing.org
[7] Parsing Expression Grammar from https://en.wikipedia.org/wiki/Parsing_expression_grammar
[8] 0D from https://github.com/guitarvydas/0D
[9] JSON from https://www.json.org/json-en.html
[10] Odin Programming Language from https://odin-lang.org
[11] Python from https://www.python.org
[12] t2t from https://github.com/guitarvydas/t2t
[13] OhmJS from https://ohmjs.org
[14] JQ from https://jqlang.github.io/jq/
See Also
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: https://guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/qtTAdxxU
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: https://tarvydas.gumroad.com
Twitter: @paul_tarvydas
The appearance of multiple parameters to functions and multiple outputs from functions is just the application of destructuring - the decomposition of a blob of bits into binary values of different “types”. In terms of bits of data, functions accept only one blob of data as input and output only one blob of data as output, regardless of what layouts are overlayed over the data blobs.