
2024-07-17-Thinking About The Game Of Pong In Hardware And Software

In aircraft and flying terminology1, there is induced drag and parasitic drag. Induced drag is the kind of drag that you want, while parasitic drag is a side-effect that you wish weren’t there. For an airplane, we want lift which is a kind of drag. We push the plane faster through the air to make a good kind of drag (lift) on the airfoil-shaped wings. As we push the plane forward faster, though, we get unwanted drag (friction) against things like the landing gear. The good kind of drag is called “induced drag”, while the unwanted kind of drag is called “parasitic drag”.
Likewise, when we use the function-based paradigm for programming, we intentionally create complexity. We add software to simple, non-reentrant CPU chips, to make them behave in reentrant, thread-safe ways. For example, we add software to handle “context switching”. Every time an operating system switches from running one process to another, it must save all of the CPU registers somewhere (including the MMU registers - which might, or might not, lead, to page faults and disk activity), then swap in the registers associated with the next process.
When we use the function-based paradigm for programming, though, we, also, unintentionally create side-effects and complexities. For one example, functions block. When a function calls another function, the caller must suspend operation until the callee returns a value. Functions can call other functions at any point in programs. Programmers might use more or fewer functions to implement the same program behaviours. This is essentially ad-hoc behaviour caused by programmers using the function-based paradigm. To counteract such ad-hoc behaviour, operating systems must resort to heavy-handed techniques like preemption. Preemption forces programmers to add extra software, and, often, to add extra hardware to their products.
There are multiple hidden costs when functions are used for programming. In this note, I examine only one such cost - bloat. I compare various various implementations of the simple game of Pong against a modern version of the same game in Löve2D/Lua.
I found a schematic for the 1972 version of Atari’s Pong game on reddit at https://www.reddit.com/r/EngineeringPorn/comments/ul49zt/the_original_pong_video_game_had_no_code_and_was/
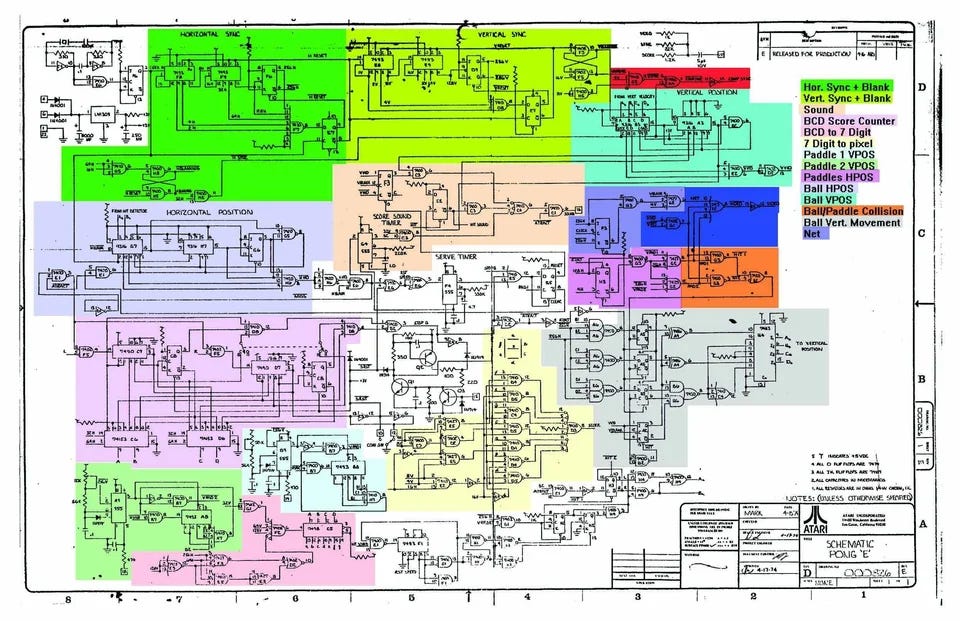
Someone colourized the schematic. Usually, schematics have no colour and are simply presented in black and white.
A non-colourized version of the schematic can be found at https://archive.org/details/pongschematics/page/n4/mode/1up?view=theater.
Observations:
Pro: The whole game fits on one sheet of paper.
Con: The notation for schematics - the equivalent of a “programming language” in software - is schizophrenic. The schematic contains implementation details (how the logic gates interact at “runtime”), physical details (the physical location on the circuit board, of each logic gate) and “declarative” details about the overall design (once you figure out what’s going on, you begin to see patterns and idioms and can gain insight into how the overall design fits together).
Pro: This is the whole game, including the “operating system” and low level timing.
Pro: The game does not contain a CPU chip. This shows that you don’t need “functional programming” or, even, a programming language to create interesting electronic devices.
Con: You have to learn how to read electronics schematics before you can understand what’s shown. Maybe you need to take some university courses. I was a teenager when I built this game for myself. I learned enough about schematic-reading from simply browsing magazines and library books. I went to university, but, I already knew how to read schematics. It ain’t hard, but, it’s not drop-dead easy.
Pro: You don’t need to know what’s inside each chip. Chip manufacturers create data sheets that provide detailed logic for the innards of each chip in abstract form. That’s usually enough detail to design electronic circuits. An example datasheet can be seen at https://www.digchip.com/datasheets/parts/datasheet/321/9316-pdf.php. If you really, really want to learn more details about the innards of the chips, you can take university courses in semiconductor behaviour, oxide atomic structure, etc. You can view the design in a layered manner, digging down only as deeply as you wish.
Con: It would take many hours / days, to reverse-engineer a non-colourized version of this schematic, but, it can be done. Either someone actually reverse-engineered the schematic and captured their conclusions using colours, or, the original designers showed, in an abstract manner, what they were thinking, by using colours.
Pro: All of the chips and all of the subsystems on the schematic are asynchronous. They free-run and are not directly affected by other parts of the circuit. This cannot be said of software written in a modern programming language, even though programmers wish it were the case2.
Pro: Referential transparency. Any IC on the schematic can be replaced by an equivalent IC. Whole chunks of the schematic can be replaced by equivalent chunks. Referential transparency is much easier to do with an electronic circuit because each IC, and, each sub-section is asynchronous and isolated and has distinct, non-synchronous input and output ports. Referential transparency is straight-forward to do with equations written on paper - using a pencil eraser and various “laws” and “lemmas” and “proofs”. Referential transparency is difficult to do using the function-based paradigm on CPUs, due to hidden dependencies caused by the paradigm, e.g. ad-hoc blocking, strict rules for routing3, direct calling of named functions, data and control flow tangling, etc.
Pro: ICs and sub-systems can have multiple inputs and multiple outputs, unlike functions which have only 1 input and 1 output4.
Pro: Testability - unit testing. Any IC or sub-section can be unit-tested in isolation. Manufacturers often specify valid output-to-input relationships and specify invalid combinations. This makes it simple to verify that ICs and sub-sections do what they claim to be designed to do.
Pro: Testability - probing. An electronic circuit can be probed while it is running. This is somewhat like printf debugging, but, unlike printf debugging, is more useful since it is not restricted to a sequential control flow. Many things are happening at the same time and multiple probes can reveal aspects about the operation of a circuit to help debug a design and to find flaws.
Con: The schematic contains weird symbols. You need to know what they mean, their meanings are not obvious. The same could be said of code written in textual programming languages, and, even, mathematics written on paper.
Pro: The electronic circuit deals with massive parallelism where many actions happen simultaneously and evolve over time. On the other hand, the synchronous, function-based paradigm treats most kinds of time as second-class quantities and hard-wires only one treatment of time5 into the notation as a first-class entity.
Pro:- Ideas, such as Christopher Alexander’s “A Pattern Language”, are more relevant and easier to implement due to the fact that ICs and sub-assemblies are completely isolated, asynchronous and LEGO®-blocky.
Pro: Production Engineering. A circuit can be, first, designed and debugged. Only later, does the design need to be optimized and production engineered, due to the fact that ICs and sub-assemblies are completely isolated, asynchronous and LEGO®-blocky.
Pro/Con: Reprogramming can be done, but, is more laborious than changing bytecodes in memory. Previous reprogramming technologies involved soldering irons, IC sockets, and various forms of rewiring.
Pro: Architectural copy/paste. It is possible to “borrow” architectural chunks of the electronic circuit design, due to the the fact that ICs and sub-assemblies are completely isolated, asynchronous and LEGO®-blocky. This kind of idiom-borrowing is more difficult with software written in sequential, synchronous function-based programming languages, because of hidden dependencies caused by the paradigm. Modern Raspberry Pi electronic technologies use the names “hats” and “shields” to denote whole architectural circuit chunks that can be snapped into designs.
Abstract Layer
I chunked the schematic into separate sections, by drawing opaque ellipses onto the schematic, following the colourization hints.
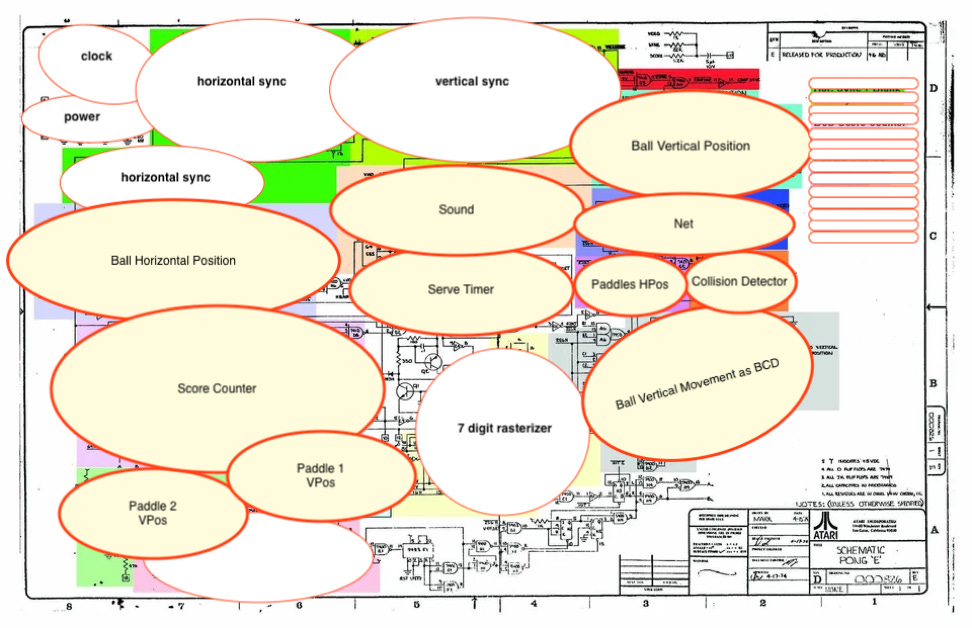
Note that I could do this only because the sub-sections are truly asynchronous.
I found something like 18 sub-sections that can be clearly understood on their own. The bits of schematic showing through at the bottom require further thought and are candidates for further chunking. So, let’s generalize and say that I found Order 20 chunks that can be understood on their own.
That sounds reasonable and understandable. I can handle thinking about 20 separate chunks, each in isolation, instead of dealing with all of the implementation details at once.
How Does Löve2D Lua Pong Measure Up?
ChatGPT tells me that the most basic version of Pong written in Löve2D is about 50 LOC. That’s about 1 page. Then, we need to add in the number of pages needed to support Löve2D. We need to add in the cost of using an O/S. The total is, roughly 490,001 pages on Linux, roughly 40,906 pages under Windows, roughly 73,261 pages under MacOS.
That’s roughly 490,000x worse, in terms of pages, than the above Atari Pong schematic. Ballparked. Let’s liberally round up to 500,000x just to keep this discussion simple.
Clearly, the numbers I’m using are questionable and can be debated. I’m only trying to make a point.
The point is: there is a cost to using function-based programming.
There are other ways to create programs, and, each one has a cost.
That 1-page, most basic version of Löve2D Pong does not even include
Score keeping
Sound
Collision detection
etc.
Adding that stuff, according to ChatGPT, raises the program size up to about 300LOC, or a total of some 5 pages. Plus the size of the operating system.
Ignoring the contribution of the operating system, the Löve2D program needs 5x the pages needed by the Atari Pong schematic.
Function-Based Programming
Function-based programming is only one kind of programming.
Function-based programming ignores some of the aspects of CPU chips and uses extra software to fake out reentrancy and thread safety.
Function-based programming has been around for a long time. Early FORTRAN used function-based programming in 1954, long before Functional Programming (FP) became popular.
Recursion and reentrancy were added to FORTRAN some years later.
Rhetorical Questions
See “2024-07-17-Rhetorical Questions”
The Tip Of The Iceberg
Pong written in Löve2D and Lua is just the tip of the iceberg. The rest of the iceberg is the underlying software that is used to simulate the function-based programming paradigm. We usually call that extra software “the operating system”.
It appears that one of the costs of using the sequential, synchronous, function-based paradigm, as currently practiced, is the unintentional creation of bloatware.
The 1972 version of Atari Pong used ICs that are just tips of icebergs, too. The stuff inside ICs is complicated and requires knowledge of molecular and atomic structure to understand.
Hardware vs. Software?
Are there differences between Pong implemented as a hardware circuit and Pong implemented in a programming language? I see several differences:
Hardware uses massive parallelism, software relies on massive sequentialism.
The innards of a Pong software program and the innards of the scaffolding for Pong are expressed in exactly the same way - using the sequential, synchronous, function-based paradigm. On the other hand, the innards of an IC are implemented in a different “language”/paradigm than the Pong circuit itself. To me, this indicates that the designers of Atari Pong used the most appropriate paradigm for each design space, instead of forcing the use of the same “language” to express the two different kinds of entities. To me, this argues that we need to create software programs using many, different programming languages, instead of pursuing the chimera of general purpose languages.
ICs have well-defined input and output APIs.
ICs don’t require all-at-once delivery of inputs and outputs. Inputs can arrive over time. Outputs can be generated over time and have no restrictions on how they are routed. This is similar to the way that servers and daemons work.
Does It Fit On A T-Shirt?
Neither, a schematic, nor a Lua program fit reasonably on a T-shirt.
This means that a new, more concise, notation is needed. The section entitled “Abstract Layer” gives a hint as to a possible direction.
The abstraction layer can only be drawn for a design in which all components begin life as asynchronous processing units. The asynchronous processing units can be grouped together into larger asynchronous units. At some point, the value of further grouping and abstraction diminishes, and we get something that gives an understandable overview of what is elided below. I believe in “The Rule of 7”, i.e. no more than 7 somethings in an eyeful, so the abstracted layer, above, doesn’t directly qualify, either. The abstracted layer, does though, show signs of being further simplified.
Conclusion: If it doesn’t fit on a T-shirt, change notations, push detail down to different layers and keep simplifying until the top-most layer does fit on a T-shirt.
Proof - Demo
A concrete example of Pong written in software using a massively parallel paradigm does not yet exist.
The substrate for creating massively parallel programs does exist in the form of 0D. 0D is actively being used for various projects, like fraze that uses t2t6.
See Also
Fraze: https://github.com/guitarvydas/fraze
Hardware actors https://guitarvydas.github.io/2024/02/17/Hardware-Actors.html
Dependencies: https://guitarvydas.github.io/2022/03/29/Dependencies.html
References: https://guitarvydas.github.io/2024/01/06/References.html
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/Jjx62ypR
Leanpub: https://leanpub.com/u/paul-tarvydas
Gumroad:
https://tarvydas.gumroad.com
Twitter: @paul_tarvydas
Thanks to Jos’h Fuller’s comments.
Function-based programming has at least several hidden dependencies that can deeply change the behaviour of a program. One such hidden dependency is the fact that functions block. The caller suspends operation until the callee returns a result. How deeply does this go? It depends. The callee might call other functions and block itself, while its caller is blocked. The blocking chain can be drastically changed depending on the functions that are used. If someone changes the number of functions in a called function, then the chain changes, unbeknownst to the original callee. The original callee’s behaviour changes. Can we stop such hidden dependencies from happening? Can we decouple software units? I discuss the other kinds of hidden dependencies elsewhere in my blogs. The function-based paradigm discourages isolation and encourages strong-coupling.
The only routing choice is: the callee must return a value to the caller. Side-effects are forbidden, hence, alternate routing strategies are forbidden.
The textual notation for functions only makes it look like functions have multiple inputs and outputs, but, is manifested on CPUs only as a destructuring operation. Currying is a different way of saying the same thing - functions have single inputs and single outputs.
sequential operation, top to bottom, left to right
text-to-text transpilation