

I believe that software has become bloated. I am wondering why. I don’t have the answers. I have some observations and doodles, though...
Early Batch Processing
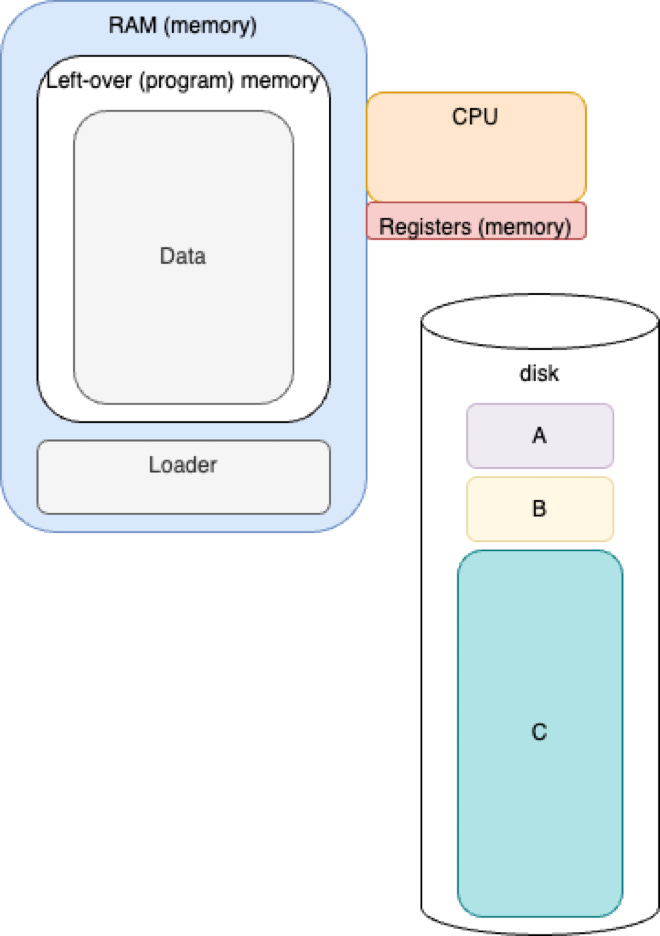
Early Batch Processing - Run Program A
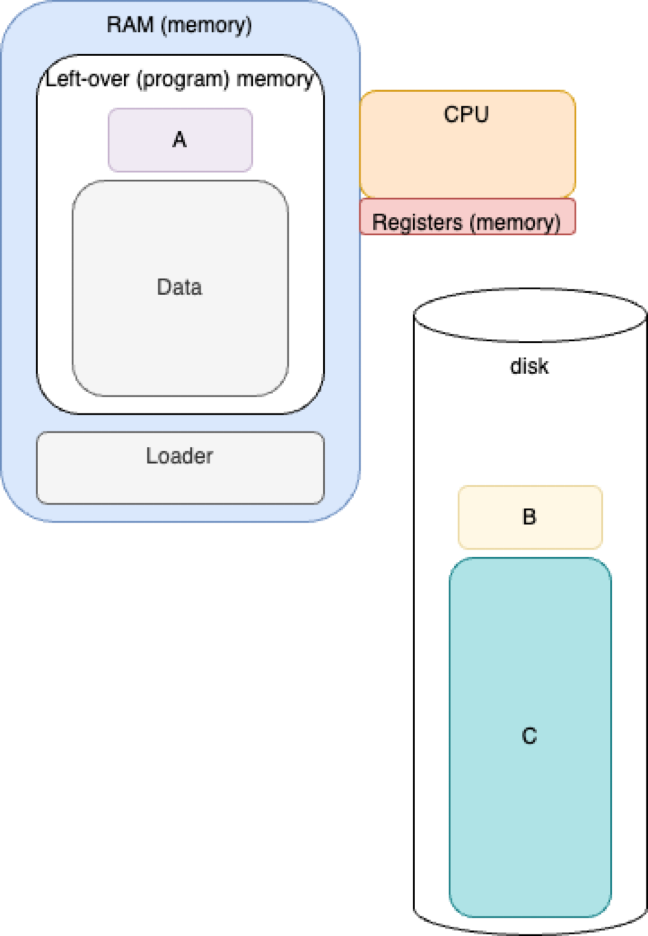
Early Batch Processing - Run Program B
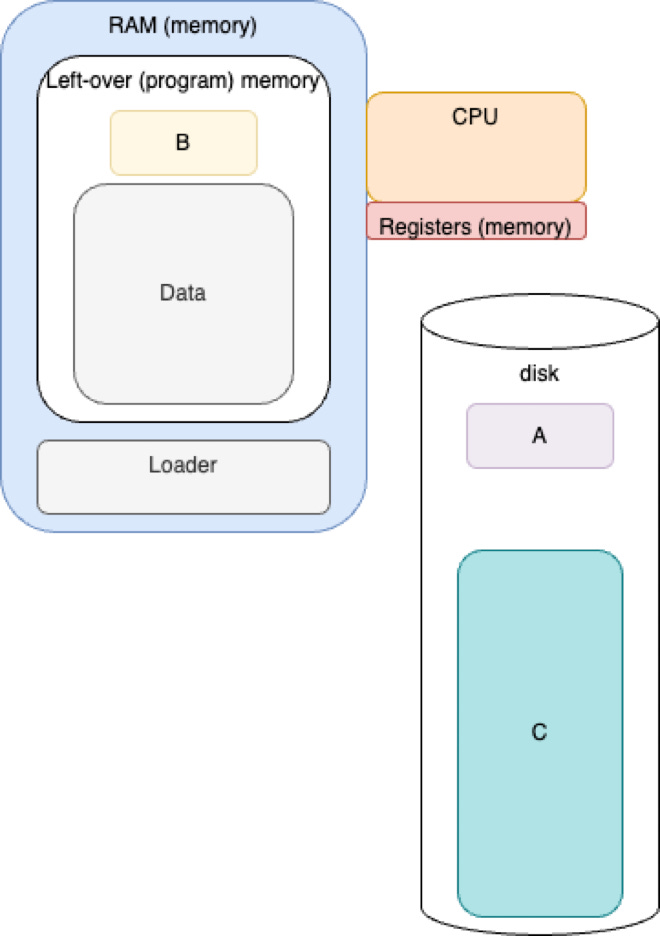
Early Batch Processing
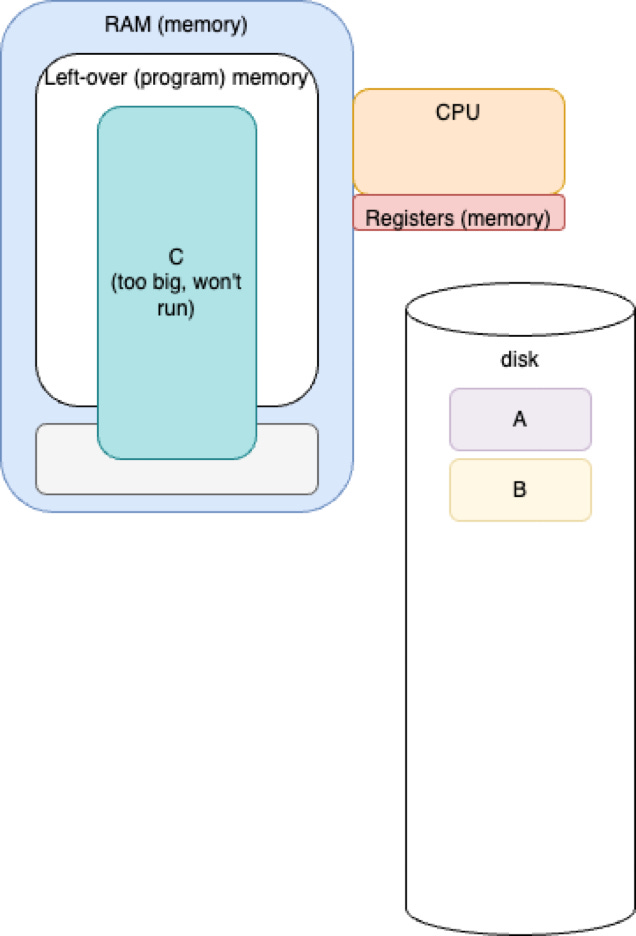
Program C too big to run.
Time-Slicing
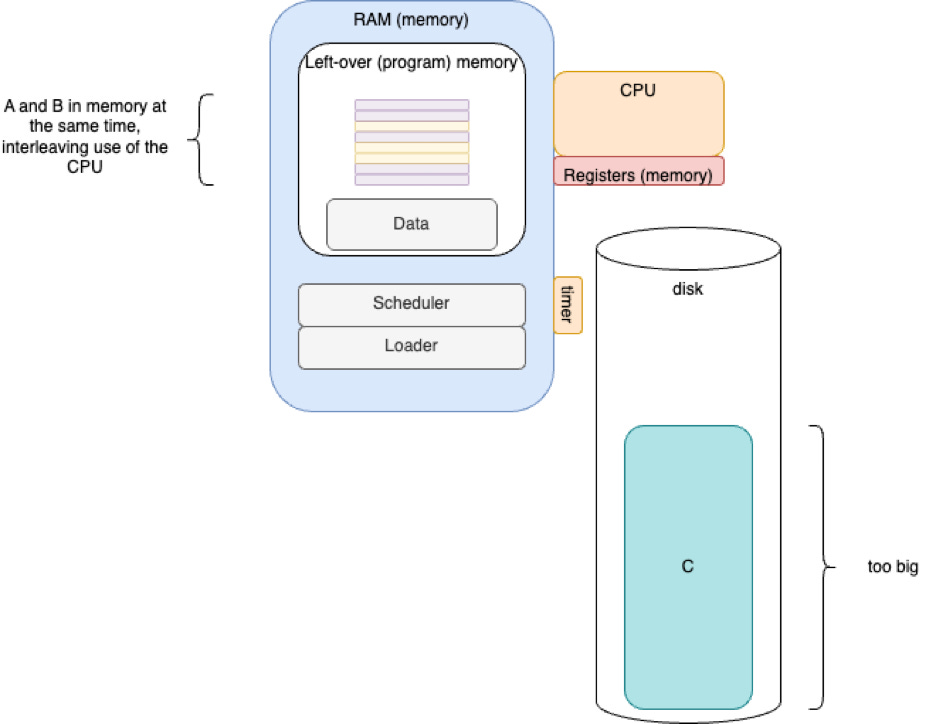
Load and run programs A and B, but, C is still too big.
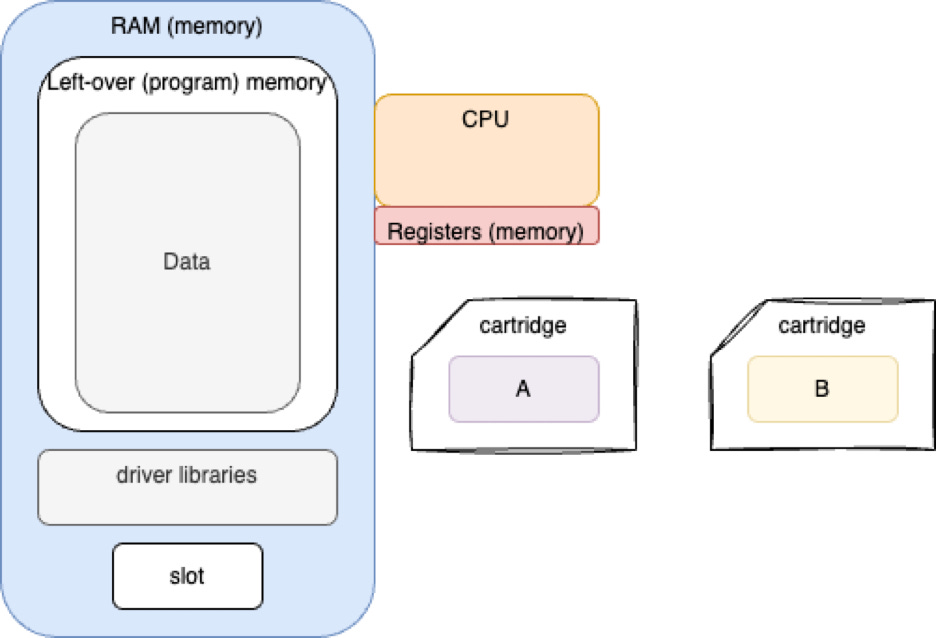
Virtual Memory
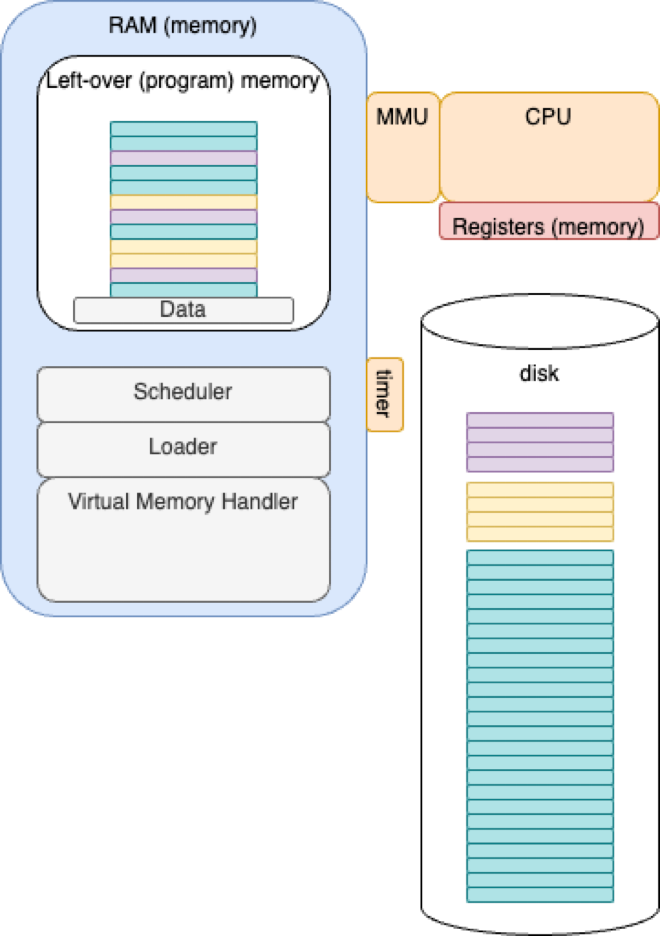
Programs A, B and C can run. Parts of each program remain on disk. Parts are loaded into memory on an as-needed basis.
Caching
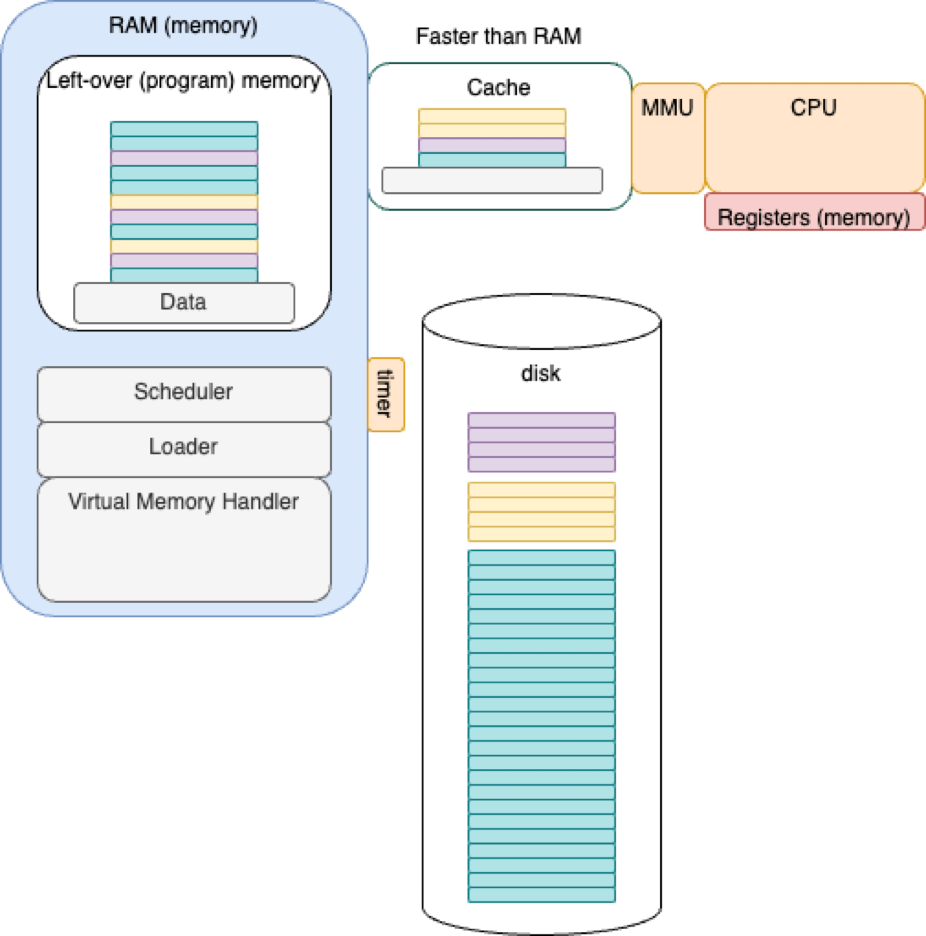
Programs run faster when parts are moved to fast memory.
Complicated software and algorithms (“cache coherency”) are required to ensure that the contents of the cache and memory are up-to-date and synchronized.
Multi-Core
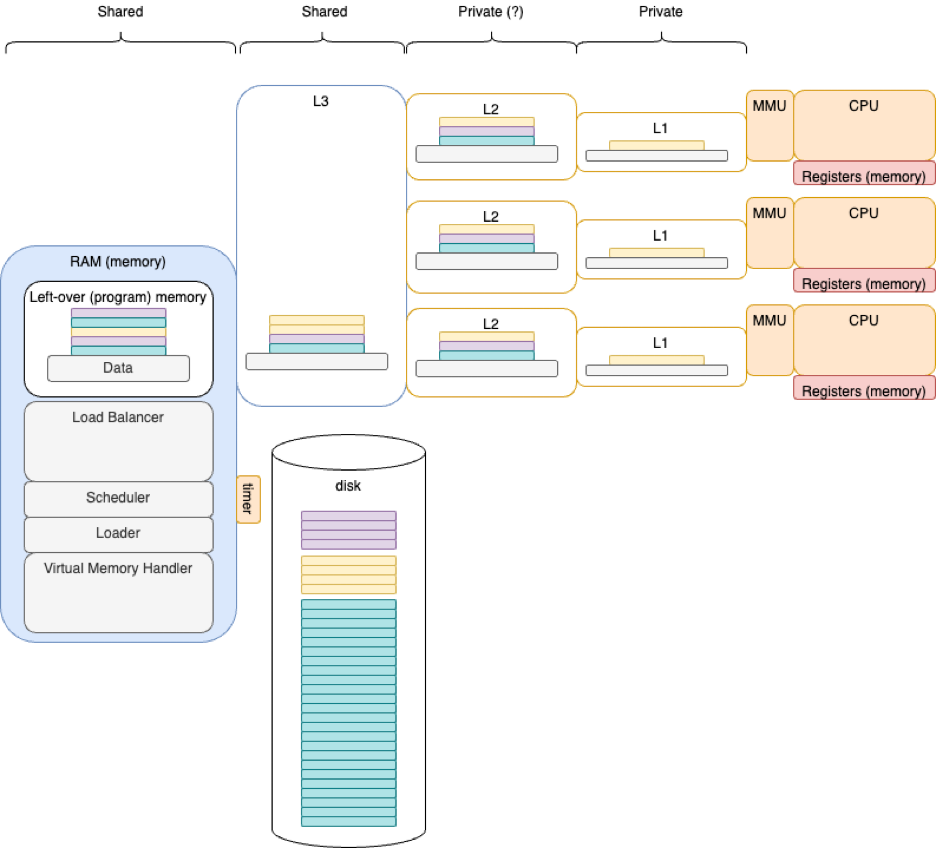
When enough of each program fits in private caches, the extra cores can run independently in parallel - as long as they don’t need to access shared memory.
If one program alters shared memory, it may affect the running time of the other programs - a form of “surprise” coupling.
Early Games
Atari Pong
An early, successful game was Atari’s Pong[1].
Atari Pong used no CPUs nor software and the design fit on one piece of paper.
The internals of Atari Pong were highly parallel.
Rhetorical Questions
Today, we punt work to GPUs. Do we still need
powerful multi-core CPUs?
powerful programming languages?
multi-processing?
Many of the features of powerful computers are helpful to developers, but, might be over-kill for end products. What parts of full-blown, development computers can we optimize away?
In the early days, compilers baked hard addresses into compiled code. This meant that the loader could not load two programs into memory if there were address conflicts. This problem was, at first, repaired by altering compilers to produce PIC (Position Independent Code). PIC was implemented as offsets from base registers. This PIC addressing operation became so common, that it was optimized by baking it into hardware and by using extra hardware MMUs (memory management units) to translate CPU addresses into real addresses in memory. This meant that loaders could load code into any place in memory, then set up the MMU mapping tables to reflect the actual location of any piece of code/data. This hardware process was further optimized by using TLB caches (TLB is more specialized than L1/L2/L3 caches).
If we went back to using explicit PIC addressing could we buy back some chip real-estate? What would we lose in the process?
MMU hardware can tell the operating system software when a piece of code/data is not in memory at all. Extra software was invented to catch such “addressing exceptions” to drag code/data in from disk and to re-adjust the MMU mapping registers. If there are not enough free MMU mapping registers available, an algorithm (“LRU”) could be used to kick out chunks of in-memory code/data and to free up MMU mapping registers. This process is called “Virtual Memory”. Note that this implies that operating systems must contain lots of extra code to handle such addressing exceptions and to access disk to make virtual memory work.
Follow-On
A possible manifestation of a simple computer for non-programmers is postulated in this article.
See Also
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com
Bibliography
[1] The original Pong video game had no code and was built using hardware circuitry. Here's the original schematics from Atari from https://www.reddit.com/r/EngineeringPorn/comments/ul49zt/the_original_pong_video_game_had_no_code_and_was/