


Understanding Cache Coherence
Overview of MSI Protocol 2024-12-29

Modern multi-core CPUs use protocols like the MESI protocol to handle cache coherence.
First, I want to understand a more basic protocol - MSI - in a general way.
To keep things simple, some details are skipped in this article.
A more thorough analysis us found in this lecture[1].
Beginning

In this sketch, there are 2 cores “P1” and “P2”. Each has a private cache. Both caches are empty.
Main memory contains the truth.
P1 Reads Variable A

The first simple transaction is that P1 reads a variable “A”.
Since P1’s cache is empty, the underlying hardware issues a “bus read” transaction which drags the information out of main memory and puts it into P1’s cache.
P1’s cache goes to state “S” (“shared”).
P1 Writes Variable A
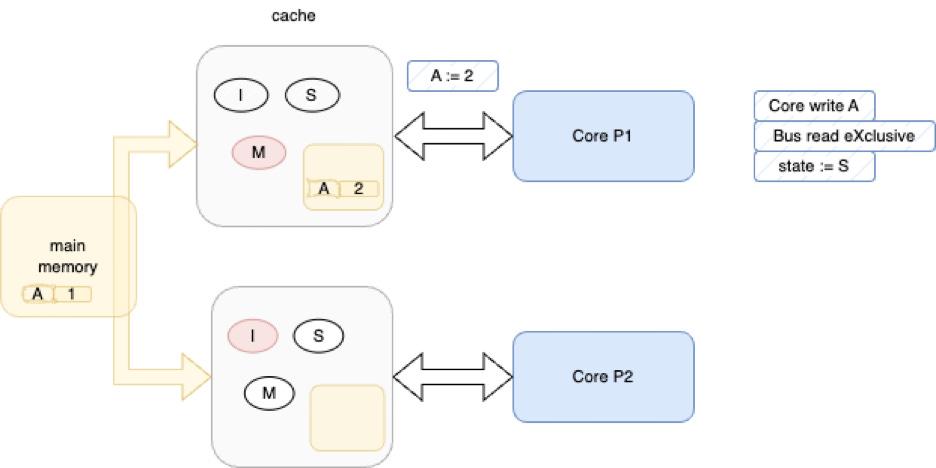
Next, P1 writes to variable “A”.
This happens locally in P1’s cache, but, the cache’s state goes to “M” (“modified”). Other caches are expected to watch (“snoop”) P1’s cache state and then update local caches and main memory as needed.
P2 Writes Variable A
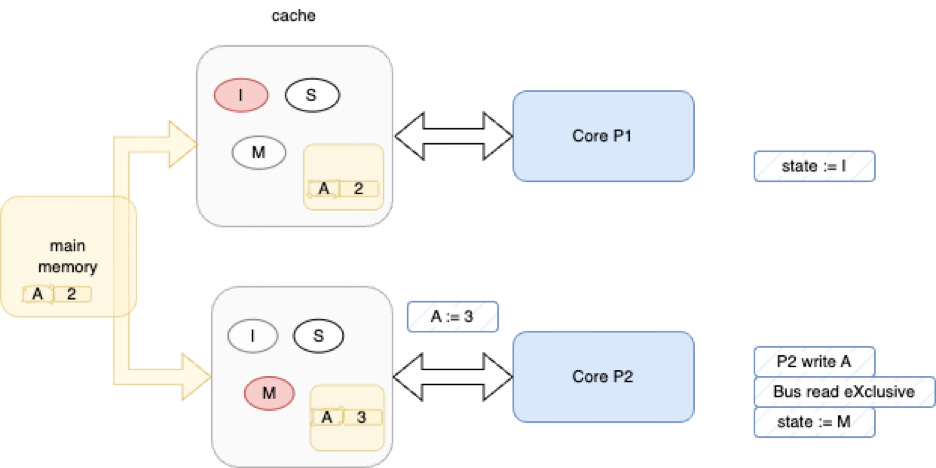
Next, P2 begins to fool with variable “A”. P2 writes to “A”.
Now, P2’s cache goes to state “M” (“modified”) and P1’s cache is forced back into state “I” (“invalid”).
P1 Reads Variable A

Next, P1 reads “A”, again.
This time, the hardware notices that P1’s cache in invalid and sucks the data out of main memory. This, in turn, causes the hardware to suck the information out of P2’s cache into main memory.
Both, P1’s cache and P2’s cache are set to “shared” state.
P2 Reads Variable A

Finally, P2 reads “A”.
This happens locally, since the data is already in P2’s cache and hasn’t been modified by any other core.
Skipped
I’ve skipped over some details.
For example, the cache contains blocks with more memory cells than are needed for a single variable. If you scribble on any part of the cache block, everything in that block is considered to have been scribbled upon. The whole block needs to be refreshed by other cores. This reality is reflected in further state changes not shown in the above sketches.
This basic protocol can be further optimized, which leads to things like the MESI protocol. I find it a lot easier to go back to first principles[2] before trying to understand the various optimizations.
Comments, Reflections
All of this complication and extra hardware is required to uphold the requirement that memory must be shared at a low level.
What would happen if we simply outlawed shared memory?
Shared memory is needed only for one class of problems - those which need to move large amounts of data around, like graphics. With today’s programming languages, every application program pays for the above complications due to the assumption that memory must be shared by default, under-the-hood.
In 1950, we “got away” with that assumption. CPUs were single-threaded and we needed to time-share CPUs due to their high cost.
Today, though, many problems don’t fall into the shared-memory-by-default category. For example, nodes on the internet don’t share memory by default, robots don’t have centralized main memories that need to be available to every “joint” (actuator) in the robot (human bodies have some 500 independent motor “joints”1).
Could we reduce the complication of the hardware in CPUs? Could we, instead of MMUs and caches, have 100s or 1,000s of 6502s (6809s, VAXs, NS16032s2, etc), on a chip with hardware-assisted messaging queues?
Comments re. Lecture Video
From the MSI lecture video[1]...
Since each core has its own private cache, the processor needs to ensure that all cores see a consistent view of memory.
This is only a biased assumption. It is based on the long-held notion that all cores share memory and that the shared memory needs to be automagically made consistent. If the cores didn't share memory, none of this would be necessary, and, cores would need to act like somewhat like "servers" that wrap previous memory and databases within a single-writer server that must accept requests to update slots in the memory. This is what happens anyway, except that it happens under-the-hood, out of sight of programmers and architects. The hardware handles update requests and hides those requests from programs, by temporarily blocking programs as necessary. This makes it hard - at the program and architectural level - to predict what's going to happen, e.g. "will a memory read take only a few nanoseconds, or, will it take much longer?". The answer is "I can't know, since the need for updates depends on what the other cores have done".
This coherency mechanism is crucial for correct program execution ...
Only if you make the assumption that cores must share memory. This assumption is works in-the-small on the same computer, but, breaks down on truly distributed systems, like the internet. For example, if a client sits in Toronto, Canada and the server sits in Berlin, Germany. Do both, client and server, need to "block" to allow the hidden hand of operating systems in the different places to update caches?
See Also
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Bibliography
[1] MSI from
[2] First Principles Thinking from https://fs.blog/first-principles
“Synovial joints” like the knee, elbow, hip, etc.
In my experience, the NS16032 (aka NS32016) had the cleanest opcode architecture of them all. The MC6809 was one of the cleanest 8-bit architectures (better than the ubiquitous 6502). Would using only 8-bit, or 4-bit, CPUs allow us to put more of them onto a chip? Who could need more than 256 or 16 unique opcodes these days? We’re punting work to specialized processors, like GPUs, so we don’t need “general purpose” opcodes and programming languages any more.