
Software Development Phases
2025-04-26

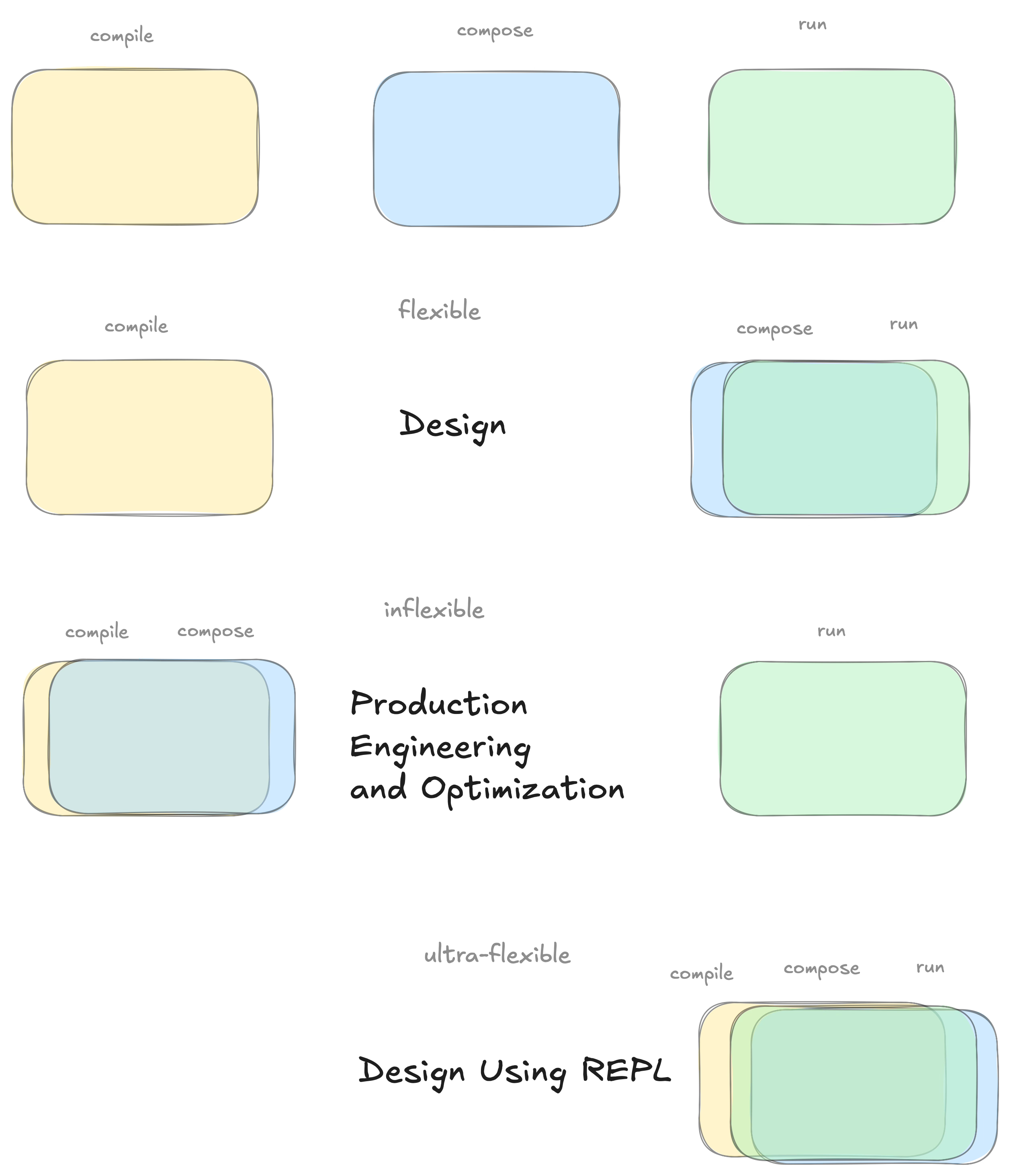
Software development has 3 phases
Compile (edit, create code)
Compose (load, resolve interrelationships)
Run.
The workflow most commonly used today tends to deemphasize the existence of the Compose phase. Most programmers think in terms of
Compile.
Load and Run.
For example, programmers produce .obj files (or files like .o on UNIX), then use linking loaders to join many .obj files into a single .exe file (or files like a.out on UNIX).
This workflow is most similar to the second diagram above. This workflow could be more flexible during the design phase.
In the early days, loaders were stand-alone programs, for example the UNIX ld command.
The ld command has been subsumed into language compilers, e.g. the cc command will link many .o files together to create a single executable.
Shared object files, like .dll, .so, .dylib, are linked to executables dynamically at runtime by operating systems.
As shown in the above diagram, this workflow emphasizes production engineering and optimization and discourages iterative design
Moving the compose phase into the runtime makes it easier to iterate code during the design phase. REPLs (Read-Eval-Print-Loops) load code at runtime and overwrite previous versions of the same code. This makes it easier to change one’s mind and to refine designs by iteratively rewriting or tweaking code on the fly.
An iterative workflow complicates stringent type-checking, but encourages design. Loading code at compile time vs. loading code at runtime has a huge psychological effect on programmers’ approach to problem solving. Emphasizing deep, early type-checking leads to waterfall design approaches, in which one thinks
that they already know how to solve a specific problem
that they don’t need to invest time into further exploration of the design
That they should invest large amounts of time to build a calcified implementation of the first thing that came to mind wherein changes due to new discoveries about the problem space tend not to be incorporated or take much longer to incorporate than would have been necessary with a more incremental approach.
Splitting Programming Workflows Into Design vs. Production
Separate the 3 phases into distinct programs
Compile
Compose
Run
Development Engineering
Perform compilation, composition and execution on-the-fly, resulting in an iterative, REPL workflow.
Repeat until happy with the design.
Lisp is like this. The compiler is built into the runtime. It is not illegal to redefine code. Type checking is done dynamically. Type-checking is added incrementally as the design is refined.
Command line workflows are like this, too, except that they feel slower than all-in-one-REPLs.
This is due to historical reasons. Can we do better with today’s hardware and software?
Processes and windows are much cheaper today than they used to be. Can we put each phase into a separate process/window then join them into a REPL using a choreographer process? This video is a short experimental example of exactly that kind of REPL. The beginnings of this experiment are shown at about 00:43 of this other video. More videos along these lines are in the “Building a DSL” playlist. These videos were intended to show how to build a DSL, but, they also show how I used the experimental REPL.
Production Engineering
Perform compilation, optimization and composition on development machines before shipping running products.
End-user computer systems don’t need loaders and don’t need command lines. Loaders and command lines are developer tools.
What’s left for end-user operating systems to do?
Context switching
Memory protection to prevent app-to-app corruption
Libraries and driver code.
End-users don’t need full-blown context switching. They essentially need a way to switch between apps and to let apps run in the background. Developers need full-blown context switching to allow them to catch and terminate run-away, buggy code. End-users shouldn’t need to catch run-away code nor should they need memory protection. The only reason for features of this magnitude to be used by end-users is that application developers sell them buggy code and applications.
Historically, library and driver code are included in distributions of operating systems because of
Distribution technology - floppy disks and CDs instead of downloadable libraries
The fact that libraries are not constructed in a stand-alone manner as “servers”, but are meant to be tightly coupled into the larger system.
Historically, it was deemed to be “too inefficient” to decouple drivers and libraries into stand-alone servers. It was considered important to hard-wire libraries and drivers into operating systems using function-call technologies and to eschew using processes. Can we do better with modern technologies? E.g. by using processes (“threads” or Parts that use queues) and ideas such as concatenative programming techniques.
See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com