
Scalable vs. Spaghetti Architecture
2026-03-11

TL;DR
The microservices debate is a distraction — spaghetti architecture is the real problem
Spaghetti comes from tight coupling; tight coupling comes from sync-by-default languages
Sync languages make us think in RPC and convince us that async is hard — it isn’t, it’s just unfamiliar
The fix is layering, not sprawl; layering requires isolation; isolation requires async-by-default
The org chart already solves this: tree structure, no peer-to-peer, async by default, information summarized upward
Software components need explicit input/output queues that preserve message order — functions strip this information out
Message order carries timing semantics; most real-world domains (internet, robotics, IoT) depend on timing
We’ve climbed this ladder before: atoms → molecules → semiconductors → transistors → ICs → programming languages
We’re overdue for the next rung — Parts-Based Programming (PBP)
L;R
The debate about microservices is a red herring.
“Microservices don’t work” — you’ve heard it, maybe you’ve said it. But that’s not the actual problem. The problem is spaghetti architecture. Sprawling architecture. Infinite canvases. Software that grows by accretion instead of by layering. Projects that get bigger by piling more stuff onto the same flat plane rather than by building one clean abstraction on top of another.
The Real Culprit: Tight Coupling
What’s the actual problem? Synchronous programming languages cause us to think in terms of RPC — remote procedure calls, function calls, blocking calls. They cause us to believe that “asynchronous is hard.” That belief is the trap. To accomplish reasonable layering, you need to employ async-by-default, and — more fundamentally — you need to begin thinking in terms of asynchrony.
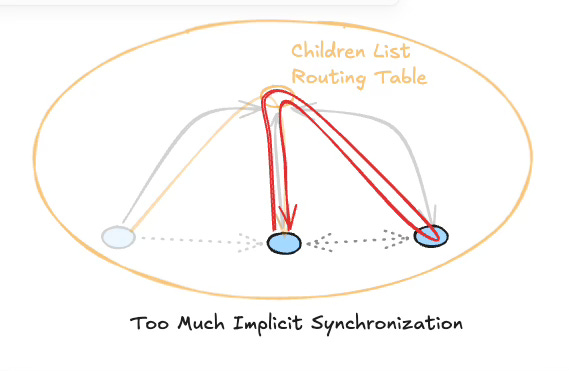
You can’t layer things properly if components are tightly coupled through implicit synchronization. When everything blocks waiting for everything else, you end up with systems where no component can be understood in isolation. The call stack becomes the architecture, and the architecture collapses into a graph the moment someone adds a callback, a shared variable, or a “quick” cross-service call.
Sync-by-default is pointing us in the wrong direction. It makes isolation hard. It makes layering hard. It makes reasoning hard.
Humanity Already Solved This
Here’s the thing: we already know how to build scalable hierarchical systems. We’ve been doing it for centuries.
The corporate org chart.
Not because corporations are paragons of efficiency — they’re not — but because the structural rules of a well-run org chart encode exactly the properties we need in software:
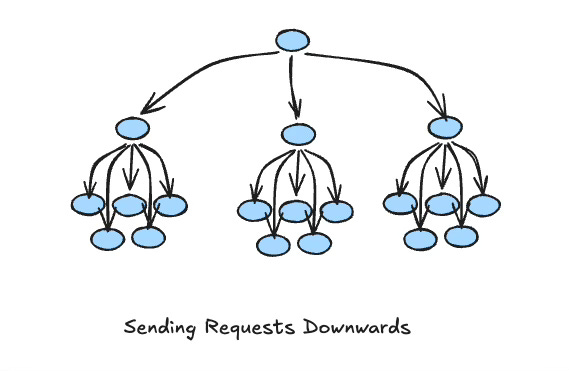
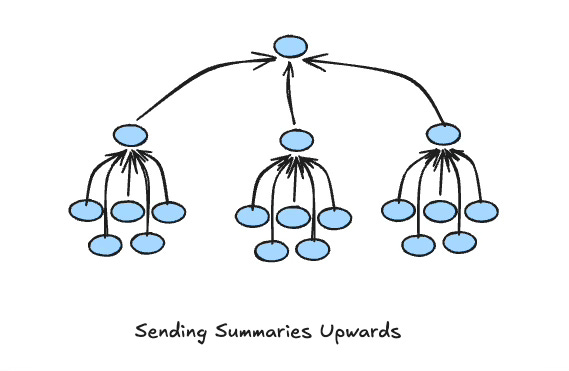
No going over the boss’s head. No micromanagement. Each layer sends requests down to subordinates and receives summaries back up. A CEO oversees five VPs. Each VP oversees five middle managers. Each middle manager oversees five workers. That’s 156 people, fully coordinated, with no node overwhelming any other node. It scales. It doesn’t intertwine.
Components cannot call peers directly.
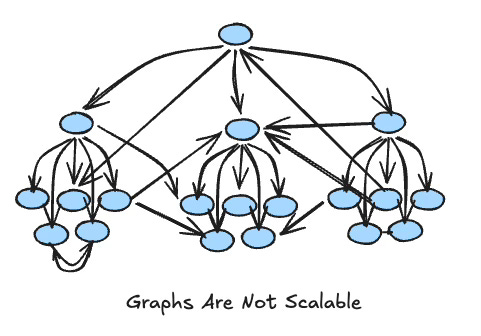
Graphs are optimizations, not clean architecture.
Leaf Nodes and Container Nodes
Think in terms of two kinds of components. Leaf nodes do actual work. Container nodes are compositions of sub-nodes — they route information between their children, and between their children and the outside world. A container node’s job is coordination and information-shaping, not low-level computation.
A node can only receive requests from its parent. A node can only send requests to its children. A node receives summary information from its children and sends summaries upward. No sideways. No reaching across.
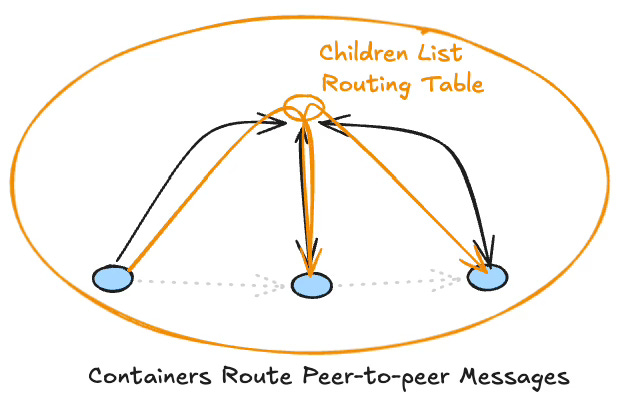
This also means that nodes — whether Leaf or Container — must have explicit input and output APIs. The only thing a component can do is leave information on its output queue, to be routed by its parent. And those queues must preserve order — order of arrival, order of generation.
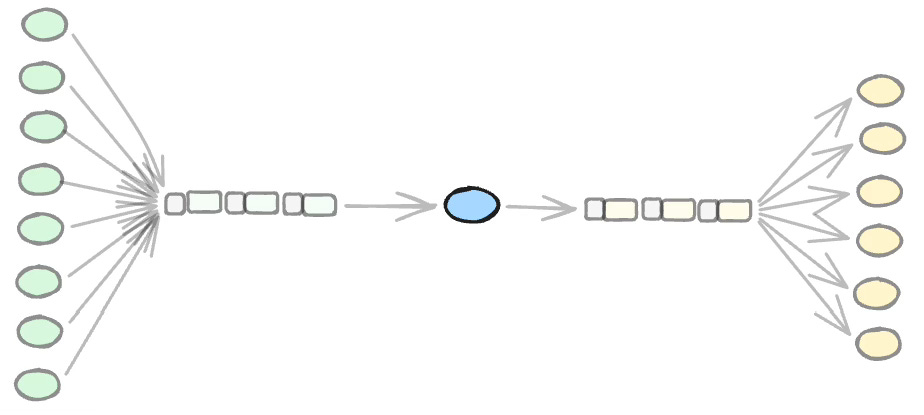
This is where functions fail us structurally. A function’s inputs and outputs arrive and depart in single blocks. Those blocks can be deconstructed into typed values, but the order information is gone. The timing semantics are gone. Message order is not decoration — it is meaning. When you discard it, nodes can no longer reason about the relative timing of information. They lose the ability to model causality.
Most real-world problem domains today involve time: the internet, robotics, IoT, NPCs, real-time systems of every kind. Calculators and ballistics computations don’t need timing information, but those use-cases form only a thin slice of what reprogrammable machines can actually do. When we use notations and languages that strip timing out by default, we waste enormous effort reconstructing it through workarounds — and those workarounds can never model the full generality of the problem. It is far simpler to use notations that don’t discard this information in the first place.
This is not a new idea. It’s just one we keep refusing to implement in software, because our languages make the spaghetti path so much easier than the structured path.
Async is the Default
Async is the default. Explicit sync is the exception. No node blocks waiting for a peer. If a node wants to communicate with a peer, it sends the information up to its parent, which routes it appropriately — filtering, restructuring, deciding what the peer actually needs to see.
That last rule is crucial and almost universally violated in software: no peer-to-peer communication. The moment you allow nodes at the same level to talk directly to each other, you have a graph. Graphs don’t layer. Trees do.
We’ve Been Here Before
We built sprawling messes of hardware. Then we invented opcodes, CPUs, and programming languages — tools that let us impose structure on the sprawl and reason at a higher level.
Now we’re at the sprawling mess level again, but in software. Infinite canvases and microservice graphs and “just add another service” architectures will not solve this. More sprawl is more sprawl, regardless of whether each individual node is “pure” or “isolated” or deployed in its own container.
The layering problem is: how do we constrain future architecture so that systems remain comprehensible as they grow?
We’ve done this before. We couldn’t reason about sprawling arrangements of atoms, so we thought in terms of molecules, then materials science, then semiconductor physics, then transistors, then ICs, then programming languages. Each layer hid the complexity below and exposed only the properties the next layer needed.
We’re overdue for the next layer.
My vote: Parts-Based Programming. Build systems out of truly isolated, async-by-default components with strictly hierarchical communication. No implicit synchronization. No peer-to-peer. Clean containment boundaries. Compositions that can be understood without reading their children’s source code.
The structure we need isn’t novel. It’s the org chart. It’s the tree. It’s the thing we reach for instinctively when we have to coordinate humans at scale — and then mysteriously abandon the moment we sit down to write code.
See Also
Email: ptcomputingsimplicity@gmail.com
Substack: paultarvydas.substack.com
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Twitter: @paul_tarvydas
Bluesky: @paultarvydas.bsky.social
Mastodon: @paultarvydas
(earlier) Blog: guitarvydas.github.io
References: https://guitarvydas.github.io/2024/01/06/References.html