
Readability - Human vs. Machine
2025-03-10

Human Readable
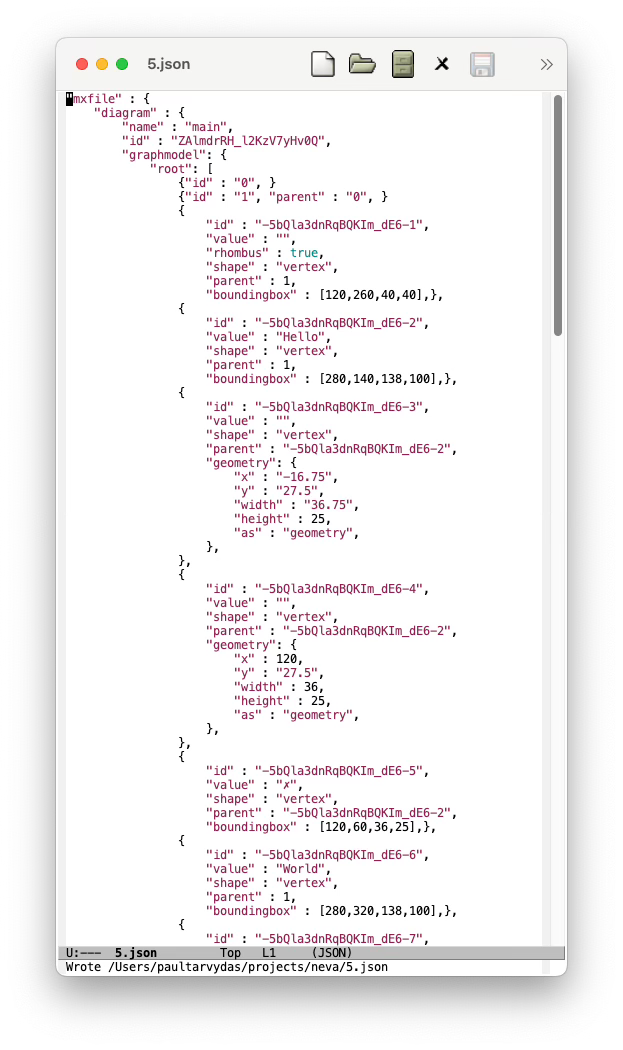
Machine Readable
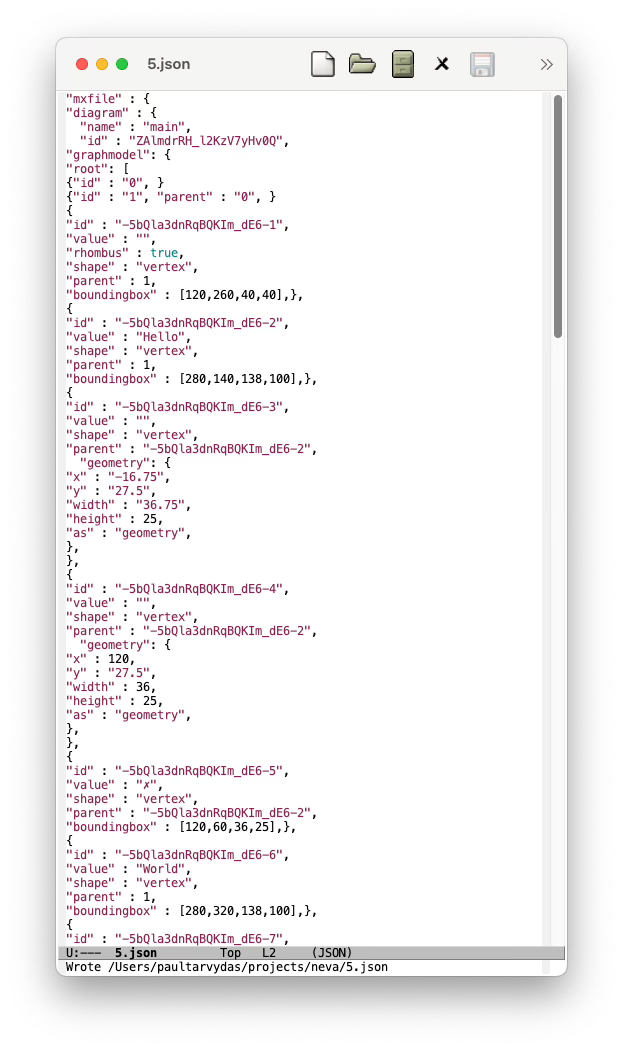
Why Does This Matter?
Both of the above screenshots contain the same, parseable information. The first screenshot has been indented to improve human comprehension, but, machines don’t care. Machines can skip over indentation syntactic sugar.
If you anticipate that indentation doesn’t matter much in some cases, then you can imagine more easily writing code that writes code. I call this Failure Driven Design.
FDD is an approach in which you assume that your code won’t work. When it does work, you ship it and move on.
How does your attitude change when you assume that your code is broken? You make it easy to go back to the drawing board. You make it easy to re-generate code for a project.
Learn something new about the problem
Fix
Regenerate
Repeat.
Compilers do this. Compilers are actually transpilers. Compilers inhale HLL source code and exhale low-level assembler code.
The UNIX® shell is on to this idea. It provides a way to inhale text and exhale new text.
A problem with shell is that its syntax is based solely on Gutenberg type-setting ideas for arranging characters on non-overlapping grids. This means that multiple inputs and multiple outputs are hard to deal with. Things like “2>” are stretching the paradigm out of shape. UNIX® processes always had multiple inputs and multiple outputs (16 or more FDs), but, the syntax of the shell makes it difficult to use many ports in a human-readable, meaningful manner. 2D diagrams with nodes and wires would be more meaningful, but, hardware wasn’t capable of easily, cheaply drawing such diagrams when UNIX® was invented. Today’s hardware is capable of manipulating such diagrams.
Another problem with UNIX® shell is that it is based on ASCII instead of something more expansive like Unicode. Even Javascript understands Unicode, and, Javascript has REGEXPs. Python, too. Maybe some of the basic UNIX® tools need to be revamped using Unicode?
Another problem with UNIX® shell tools is that they are mostly based on outdated REGEXP technology. Most modern programming languages use structuring and scoping syntax, like “{ ... }”. REGEXP doesn’t make it easy to parse that kind of text.
PEG, though, does make it easy. OhmJS is an improvement on PEG. OhmJS makes it even more easy to parse this kind of stuff.
Using OhmJS, you can say some things more concisely than with CFGs. In only a couple of lines of OhmJS, you can say something like “match an open brace, followed by lots of stuff, then match a closing brace”. Using CFGs, though, you have to say - exactly, in gruelling detail - what “stuff” is.
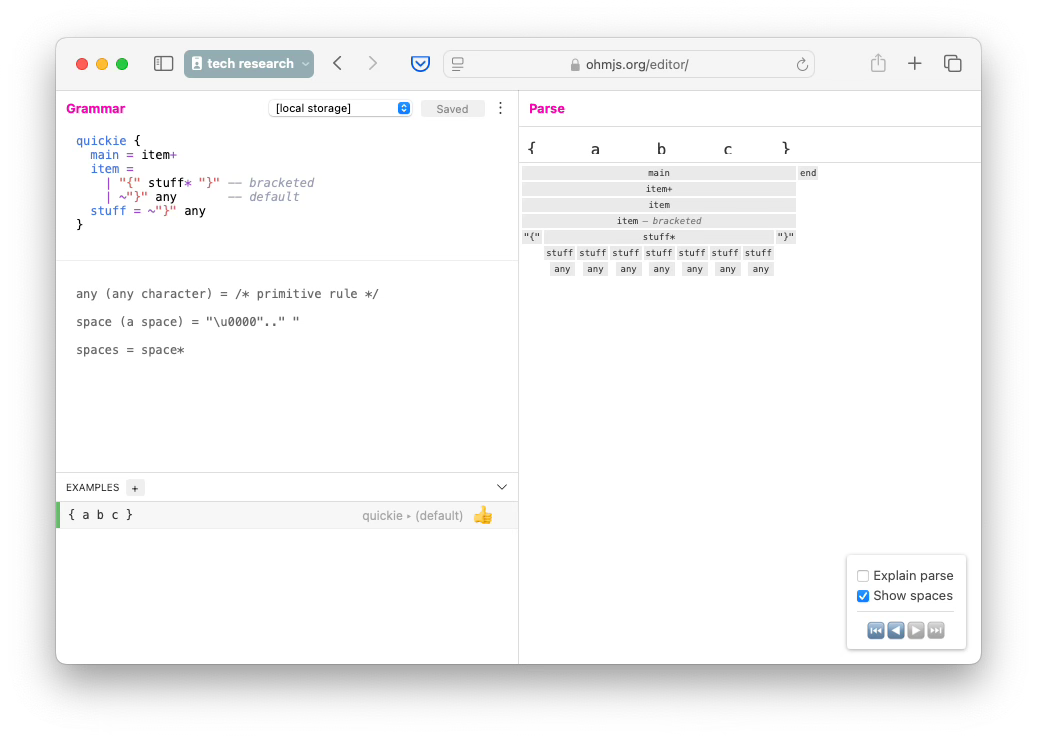
I’ve been experimenting with text-to-text transpilation with tools like t2t, which include nano-DSLs for parsing and for rewriting text.
See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com