
Multiple Notations In A Single Project
2026-03-28

I favour using many - terse - notations within a single project. One notation for each kind of issue within the project.
It’s about focusing in on a specific issue. Terseness allows you to focus better. Terseness allows you to write down what you think and to try it out. If you don’t like it or learn something new, terseness makes it thinkable to just erase what you wrote and to write something new. Too much detail, too early, discourages retrying, since you’ve already invested too much effort in the code. Making the notation terse rebalances the equation - you can spend more time thinking (and trying out) instead of spending time worrying about dotting all the i’s and crossing the t’s.
If you think that you don’t need to retry, you are engaging in Waterfall development.
A terse notation is more expressive,,, but only for that specific issue. You need a different notation when you switch to thinking about some other issue.
Example
I wanted to think about how to compile diagrams to code.
I could suck in diagrams in .graphML form or .svg form - so that wasn’t much of an issue.
At one point, though, I needed to fill in “semantic” information that was in the diagram but scattered about and not conveniently arranged how I would like. That is an “inferencing” problem.
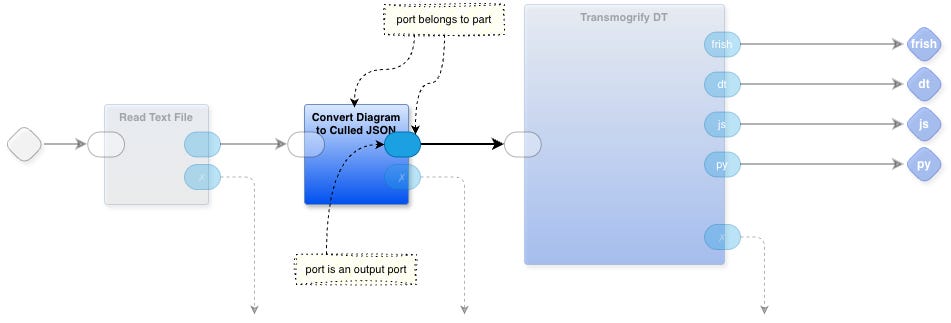
Prolog notation is much, much better for dealing with inferencing than anything else I’ve found, e.g. loops within loops, recursive functions, etc. So, I expressed the pattern matching relationships in a way that made sense to me. I let a Prolog engine chew through the relationships and produce the semantic info in a way that I wanted.
For example, ‘this pill-shaped figure is a “port” that belongs to that rectangular figure (a “part”). And, this port is an output port because the tail end of an arrow is attached to it. Repeat for every pill-shaped figure and create facts that relate each port to each part and facts that say in a convenient way which direction each port is (in, out).
Later, though, I just wanted to write this stuff out into a text file (fyi: I’m using JSON, because it’s easy and ubiquitous) and fool around more with the text. Prolog makes it difficult to deal with strings. JavaScript (!) is easier for this kind of thing.
For me, Prolog was the syntax of choice for the inferencing stuff, but JS (Python, etc. - (fyi: in fact, I’m using OhmJS and my T2T tools)) was the syntax of choice for the rest of the text-manipulation stuff. If I had to choose only one language for this, I would have had to struggle with either Prolog or with JS. I wanted to use both (this is but a simple example, I actually use lots of languages).
In my view, a GPL - General Purpose Language - like Rust, Python, Haskell, C++ can’t express everything I need to think about without causing me extra work. You can see GPL design heading towards either milquetoast unions of a variety of features, or, too much emphasis on only one kind of feature (e.g. type checking, user-defined structs, etc.).
GPLs are good for optimizing and for creating production-ready code, but not so good for thinking about problems and their solutions. The way I see it, creating a program consists of (at least) two major activities:
Thinking about the problem and verifying that my intended solution works well enough (Design Engineering)
Creating a production-ready version of the final, chosen design. Using automated tools to help me find loopholes (Production Engineering)
(I’m consciously skipping over other issues, like release, maintenance, security, etc.).
See Also
Email: ptcomputingsimplicity@gmail.com
Substack: paultarvydas.substack.com
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Twitter: @paul_tarvydas
Bluesky: @paultarvydas.bsky.social
Mastodon: @paultarvydas
(earlier) Blog: guitarvydas.github.io
References: https://guitarvydas.github.io/2024/01/06/References.html