
Modernizing Program Compilation
2026-06-18

1960s
In the 1960s, the approach to compilation of programming languages was based on a text-only workflow.

DPL Compilation Using 1960s Approach
The 1960s approach can, also, be used to compile DPLs - Diagrammatic Programming Languages.

Other options for program compilation exist. These weren’t practical / possible back in 1960.
Modernized Approach - Using Existing PLs as Assembly Language
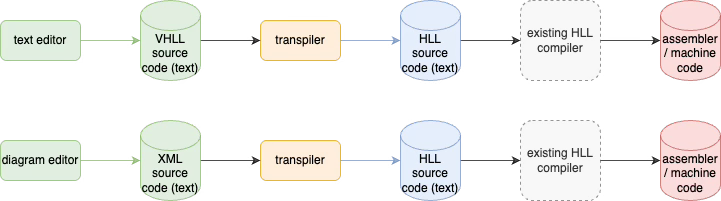
Many compilers exist. We don’t need to build more compilers.
If we want to develop new languages, we should simply use existing compilers.
This can be accomplished by using existing languages as assemblers. There is no reason to reinvent the wheel.
Transpilers are simple macro processors. Transpilers rewrite code from one form into another. This is the way that early compilers worked. Early compilers transpiled HLL code into assembler code.
Compilers, as we know them, do more than just simple transpilation. Compilers, also, lint code. Compilers include type-checkers which help programmers find inconsistencies in their logic.
Compilers do two things:
Compilers lint the source code.
Compilers transpile source code into another form, e.g. machine code, assembler, etc.
Currently, programming languages conflate the two actions together into single apps called compilers. Compilers contain two syntaxes.
One syntax for linting and type-checking
Another syntax for creating machine code (or assembly code).
I suggest that when the two syntaxes are conflated into a single programming language, complexity of the language becomes exponentially higher.
I suggest that the two syntaxes be separated into
A linting and type-checking syntax.
A machine code creation syntax.
It seems to me that type-checking is essentially a relational programming issue.
It seems to me that a machine code creation syntax is an imperative syntax which is unrelated to relational programming.
If we separate the two kinds of syntax, then we can begin to imagine new kinds of programming workflows.
Multiple Targets
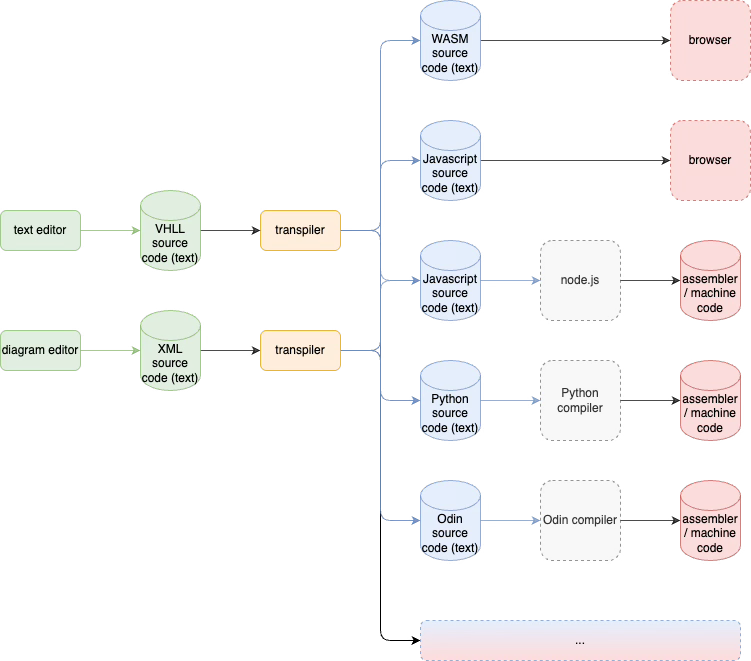
For example, we can imagine a workflow which compiles a text-based or diagram-based program specification into several targets, like WASM, Javascript, Python, Odin, Rust, etc.
The compiler would use transpilation to convert VHLL source code into HLL source code.
A separate language could be used to describe type relationships within the VHLL source code to check for semantic errors before transpilation.
We conflate the transpilation and type-checking languages into a single language, due to biases from the 1960s. In 1960 it was difficult to implement multi-language workflows, so everything was crammed into single programming languages.
UNIX shows us how to implement multi-language workflows, but, we continue to cling to 1960s, pre-UNIX ideas of what programming workflows should be. In 1960 and beyond, UNIX relied on heavy-weight processes to implement multi-language workflows. Today, process spawning runs quickly and even more quickly if we use light-weight closures instead of heavy-weight processes. Software developers like all of the memory protection and virtual memory provided by UNIX, but, end-users don’t actually need all of that scaffolding. We need workflows that appease developers’ desires, yet, can be trimmed down to what end-users actually need.
Experiment - Arith
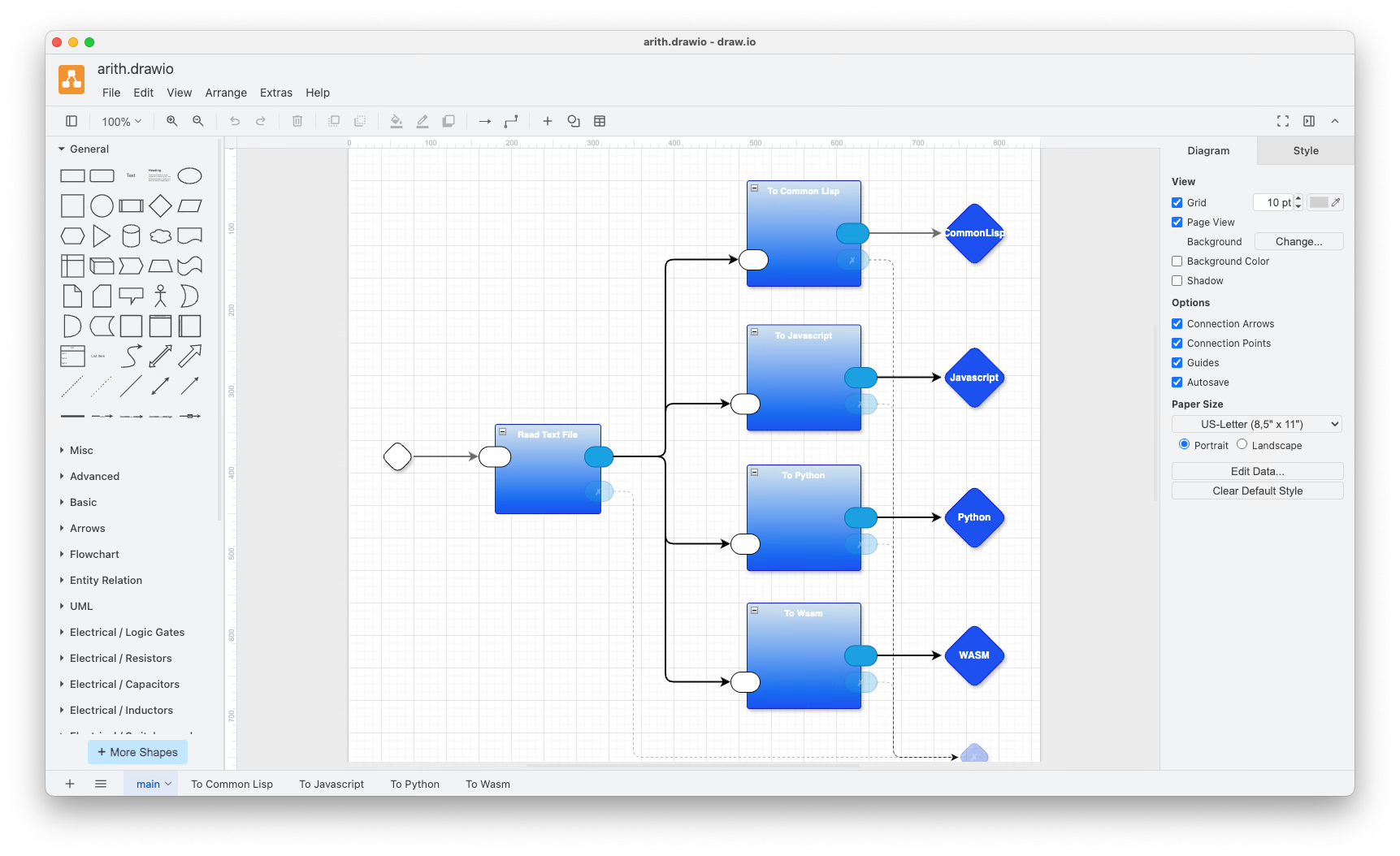
This is a working example, with code that can be found in a github repository.
The drawio diagram editor is used to create the drawing. Drawio saves diagrams as text files in graphML format (graphML is XML).
The input source text is read by the ‘Read Text File’ part, then a copy of the source code is fanned-out and sent to four transpiler parts.
Fan-out was eschewed in the 1960s because of concerns for memory efficiency. The most straightforward way to implement fan-out is to make copies of the data (strings containing code in this case), then to expect a garbage collector to clean up and to reclaim the copies after they are no long needed. In electronics, fan-out is common but works without copying. In electronics, tiny bits of the electrical current are nipped off and used to feed each downstream input. This is akin to taking a cup of water out of a running river. If you take too much water out of the river, you change the river. In electronics, the concept of taking only a tiny bit of current out of the electrical stream is called “high impedance”. If you have too many downstream components nipping out portions of the electrical stream, you alter the stream. If you have a downstream component that takes too much out of the electrical stream (“low impedance”) then you, also, alter the stream. Electrical engineering provides methods for calculating impedances and how to determine when too much current is being drawn out of a circuit.
FP - functional programming - notation does not encourage the concept of fan-out. FP typically expects a function to have only one output that is returned to the caller. The above code, though, shows a multi-headed pipeline where data flows from left to right, and is not returned to the upstream part. It is simple to implement fan-out to multiple receivers in FP, but programmers tend to overlook such possibilities, due to the synchronous, sequential mind-set encouraged by FP.
Operating systems, like UNIX, make it easier to implement fan-out since part of the work is done through the concept of processes. Processes are blobs of tightly-coupled, function-based code (pure FP or not) that send packets of data to one another via IPC mechanisms. Operating systems treat processes as lists of anonymous functions that are invoked at the whim of operating system schedulers. Unfortunately, UNIX doesn’t implicitly perform the second part of the work - making multiple copies of the data packets. To copy data packets, programmers must explicitly use programs like tee. Again, in 1960 it was considered sinful to use up memory making implicit copies of data and to rely on garbage collectors that used anything but the Biblical Flood method, i.e. waiting for a process to terminate, then reclaiming all of the memory used by the process in one fell swoop.
Ironically, pure FP can be employed to implement incremental garbage collection and to reduce excess memory use by using structure sharing, which is an under-emphasized key ingredient in 1956 Lisp 1.5 lists and functions. The simplicity of this approach was obfuscated through Lisp 1.5’s use of a mark-and-sweep garbage collector. To see FP-oriented garbage collection in its full glory, refer to the implementation of garbage collection in Sector Lisp.
Sector Lisp happens to be implemented in assembler, but the real secret of Sector Lisp’s smallness and efficiency is due to other factors.
Conclusion
Modern programming environments are much more powerful than what was available in 1960. Programmers should be allowed the luxury of using tools that help them design and build solutions faster without regard for the niggly details of how to build compilers, deal with memory management, etc.
Appendix - References
[A video summary is here]
T2t - text to text transpilation
Arith example - code for arithmetic experiment, shown above
Appendix - See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com