
Lisp Source Code
2025-06-22

Video Summary
This article is briefly summarized as a video.
Lisp Source Code Format
The presentation This Is Not A Clojure Talk by Jack Rusher about REPL-driven development contains many seemingly insignificant details that all add up to a productive IDE for program development.
One point from the talk is that Clojure - Lisp - represents source code as internal data structures.
Lisp code is stored on disk as strings of characters in a text file, but the lisp reader converts these strings into internal data structures called lists.
The main feature of lisp is that it contains many operators that deal with lists. Hence, lisp can be used to edit its own code, since source code is converted to lists instead of remaining in the form of strings.
The sketch below shows how code is represented as list data structures internally for a trivial line of code.
The line of code (print (quote (a b c))) is read in as text then converted to lists that are represented in the sketch.
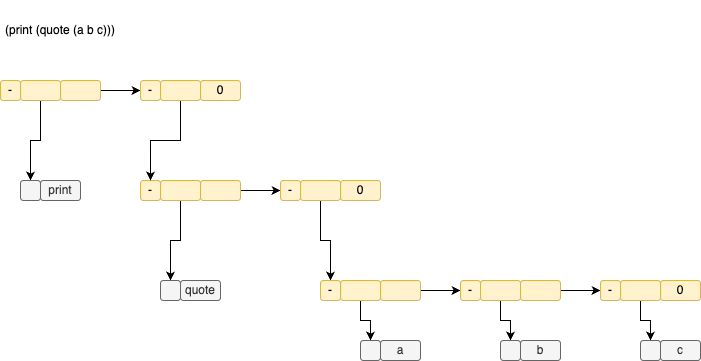
The yellow boxes are list cells with a front part and and back part, called car and cdr respectively.
The gray boxes represent constants, called atoms. The sketch doesn’t show the gory details of how atoms are actually laid out in memory.
In McCarthy’s original Lisp 1.5 implementation and in the modernized version Sector Lisp, there are only two types:
Atoms
Lists
The two types are represented by a single bit - the sign bit. Memory is divided in half. The lisp interpreter refers to cells using indexes. If an index is negative, then it refers to list space. If an index is positive, then it refers to atom space. Indexes -0 and +0 refer to a special value called nil.
The back part - the cdr - of a list pair is the index of the next item in the list. A value of 0 (nil) marks the end of the list.
At the machine code level, programmers call these indexes pointers.
Aside: this is but a sketch that skims over gory details. You can get accurate details by studying the implementation of Sector Lisp, which is expressed in assembler, Javascript and C.
Modern implementations of Lisp define more types, like numbers and strings, hence, production versions of lisp use more bits for type markers. In such production versions of Lisp / Clojure, using only -ve and +ve indexes is not enough for differentiating between all of the low-level types that are supported.
To emphasize, lisp code is not stored internally as strings, like “(print (quote (a b c)))”. Lisp code is converted to list data structures. The string version of lisp code is only a serialization format used to save code in files in the file system. The lisp compiler and interpreter works with source code that is in list format. Only the lisp reader touches lisp source code represented as strings, and converts the strings to internal list format before handing the code off to the lisp compiler and interpreter.
Aside: the lisp reader is generally called a scanner in today’s terminology.
Atom constants are hashed. There is only one copy of each atom with the same name. In early lisps, it is possible to jump through hoops and to modify / mutate the contents of atom constants. In modern lisps, the loopholes have been closed and this kind of mutation is verboten.
This seemingly insignificant fact about the internal format of lisp source code makes it easier to do edits and operations like those in Rusher’s talk. The language can modify its own source code. The language stores data in the same format - list format. Lisp contains many functions for dealing with lists. This means that lisp can easily deal with data and it can easily deal with source code.
Furthermore, since the compiler deals with lists instead of strings, lisp programmers can create compiler plug-ins. These plug-ins are called macros.
Aside: I argue that concentration on research into type-checking, immutability, functional programming, synchronousity, sequentialism, etc. has caused programmers to overlook the potential for more productive development environments, such as that described in this article and Rusher’s talk.
Aside: lisp source code, represented as lists is essentially tree-driven - AST-driven - code. Lispers love this feature, since it provides the power of free-wheeling assembler. Many other programmers see this feature as a foot-gun, yet, languages like Rebol and Janet come with PEG parsing built in, Racket touts language-oriented programming, and, Python allow programmers to access its ASTs. Research into projectional editing is attempting to reproduce the power of normalized code representation already found in the original release of Lisp 1.5 (around 1956).
Aside: I argue that it is possible to deal with code represented as strings in the same way that lisp can deal with code represented as lists, using PEG technologies like OhmJS. I leave discussion of such techniques to other articles. The main point in this article is that normalized representation of data and code leads to a smoother, more productive development workflow.
See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com