
JVM vs Lisp Eval
2025-01-16

Pond’ring Aloud. Brainstorming. I don’t, yet, know where this is going. This is an observation that might - or might not - lead to interesting ideas. I got to thinking about this due to my previous article on Practical Concurrency and caching.
Both, JVM and Lisp Eval, are interpreters.
The data structure interpreted by JVM is an array.
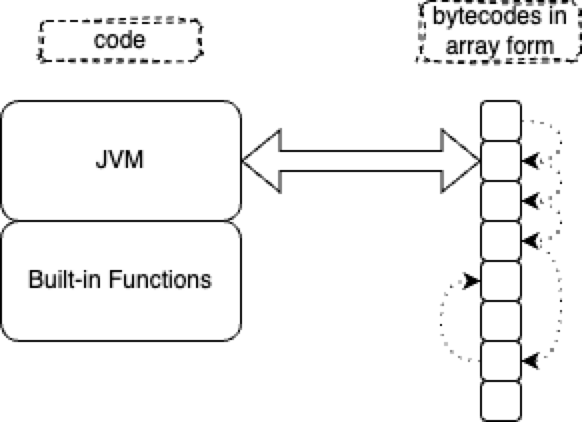
Whilst the data structure interpreted by Lisp is a list.
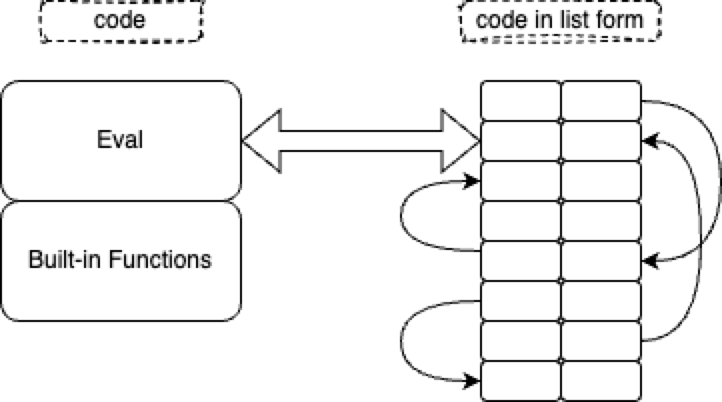
An array is just an optimized list. The optimization is that the address to the next item (the CDR) is stripped out of the data structure. The trade-off is that you need to keep an index - often called the IP (Instruction Pointer) - somewhere in a variable or a register which must be sequenced. And, array items need to be contiguous in memory. A list retains CDRs, hence, can point to various locations and doesn’t imply sequencing - items don’t need to be contiguous in memory.
In the above sketches, I’m being unfair to lists. For my convenience, I’ve drawn list cells as being 4 times as wide as bytecodes. The CAR is 2 units wide, the CDR is 2 units wide, with a total size of 2+2=4. My drawing of bytecodes shows bytecodes as being only 1 unit wide.
List cells with explicit CDRs will always be wider than bytecodes with stripped-off CDRs, but, the ratio is not necessarily 1:4.
Where does this knowledge take us? I don’t know yet, but, I do note that Sector Lisp[1] is incredibly tiny. Also, the flexibility of lists make it a lot easier to generate code-as-lists. Generating code-as-array-elements is painful, since one needs to worry about insertion and deletion issues (C’s malloc() is an example of pain inflicted by array-think).
I think that generating code is important[2]. I learned about generating code through using Lisp macros and through learning about compilers. Today, I think about generating code through text-to-text transpilation[3]. Thinking this way tends to open up different avenues of thought / solutions-to-problems.
We had allergies to lists in the early days of computers, due to an over-emphasis on memory efficiency. Today, we have lots more memory - essentially an exponential growth in memory size. Array-think caused a lot of headaches in the past and mutated just about all programming languages and caused us to spend many extra brain-cycles to work around the gotchas of array-think. We didn’t even know much about garbage collection (Jart’s “ABC” GC is better than McCarthy’s mark-and-sweep).
What would a programming language designed for today’s hardware look like, instead of yet another programming language designed for 1950s hardware? Can we squeeze code in a cache-friendly manner? Can we get rid of caches altogether and replace the saved IC space with more cores? Or, shrink IC space and just reduce the end-user co$t?
Comments, observations, welcome...
See Also
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Bibliography
[1] sector lisp from https://justine.lol/sectorlisp2/
[2] Failure Driven Design from https://guitarvydas.github.io/2021/04/23/Failure-Driven-Design.html.
[3] t2t from https://github.com/guitarvydas/t2t