
Enumerate Every Case
2025-06-30

TL;DR
I’ve been pondering hash entry deletion using tombstones as per ch. 20 of the Crafting Interpreters book. To me, it feels like the code hides design decisions and forces readers to reverse-engineer the code. The code is optimized for execution, but, human readability suffers from this optimization. I'm currently playing with a set of truth-tables that explicitly state every decision along the way. Our tools and workflow should convert very-explicit Design into optimized code. This was not reasonable to do in 1960, but should be reasonable to do in 2025. I include WIP .png files of the truth tables and a rough-in done in terms of PBP (0D). A goal is to actually finish the implementation in PBP and see that it runs. I generated the equivalent code in Python (actually my LLM wrote the .py code) but I haven't progressed much further due to limited time and too much low-hanging fruit on other fronts. If anyone wants to poke at this and finish it sooner than I can, I would be happy to share the code "as is”...
Hash Table Deletion Technique
A hash table entry deletion technique is discussed in Crafting Interpreters chapter 20.4.5.
This chapter’s code got me thinking about a different approach to solving this problem. Instead of writing the code first, I’m wondering if it might be better to break it down and explain it to someone else. That way, they can understand what the code was trying to achieve without having to reverse-engineer it.
The book’s technique uses tombstones. Deleted entries aren’t completely erased, but marked as absent. This preserves collision information. A collision happens when inserting data into the hash table. If a hash function maps a datum, like a string, to an already occupied slot, the algorithm searches forward for the next unused slot and inserts the new datum. Subsequent lookups involve the same search while checking every slot to ensure that the expected datum is present.
Studying a compiler written in a functional programming style and denotational semantics (including my favourite book on the subject), I concluded that the big win is the idea of being very explicit and enumerating every case. In FP-style compilers, this means passing environment args to all functions, even if they just pass this information through to other functions.
FP textual notation makes this painfully repetitive to write, hence, programmers use global variable and free variables and they tend to prematurely optimize the code, in order to reduce repetition.
When I think about the above hash table deletion algorithm in a painfully explicit manner, I find myself resorting to truth tables and data spin-offs. This line of thinking leads me to a software LEGO® design that has one common element and two possible downstream “filters”
interning
lookup
Interning a string always succeeds and returns a pointer to the interned string. Interning is used to ensure that there is only one copy of each string in a system. This is how Lisp creates symbols.
Lookup returns a success or fail result. On success, a pointer to the string is returned. On fail, the pointer itself is meaningless, since no string was found.
The process of generating these results does a search which spins off data before declaring success or failure of the search. This is different from success or failure of lookup - the search is a pre-cursor to lookup and/or interning.
The search loops through the table, sending out the first tombstone slot (‘tslot’) and the first non-tombstone slot (‘slot’) it finds. In the case of intern, the non-tombstone slot is empty or occupied by the same string. In the case of lookup, the slot is empty if the search failed or occupied if the search succeeded. Afterward, it declares found or not found (found) by sending an event from the appropriate port. A common front end ensures that ‘tslot’ and ‘slot’ are sent before the ‘found’ or ‘found’ event. It also guarantees to fire only one of the ‘found’ or ‘found’ events. Unlike in functional programming, a port doesn’t need to produce a result; not firing is equivalent to nothingness. Once an event arrives, we can form a truth table to determine the appropriate action (intern or lookup).
The software LEGO® (PBP) design can be sketched as:
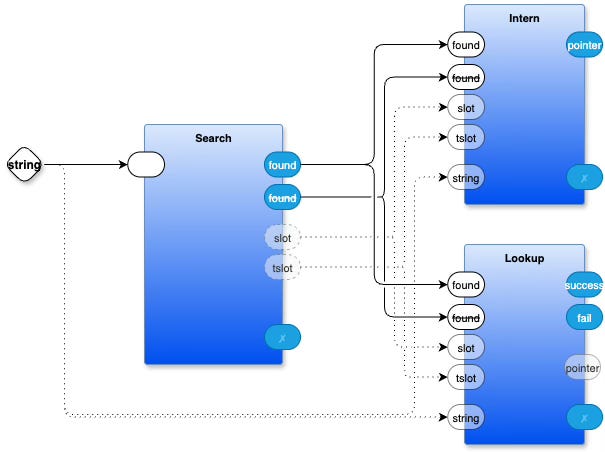
[Note: I haven’t tried to tie up all of the loose ends, like where ✗ mevents are sent, nor what the final outputs are.]
And the truth tables are
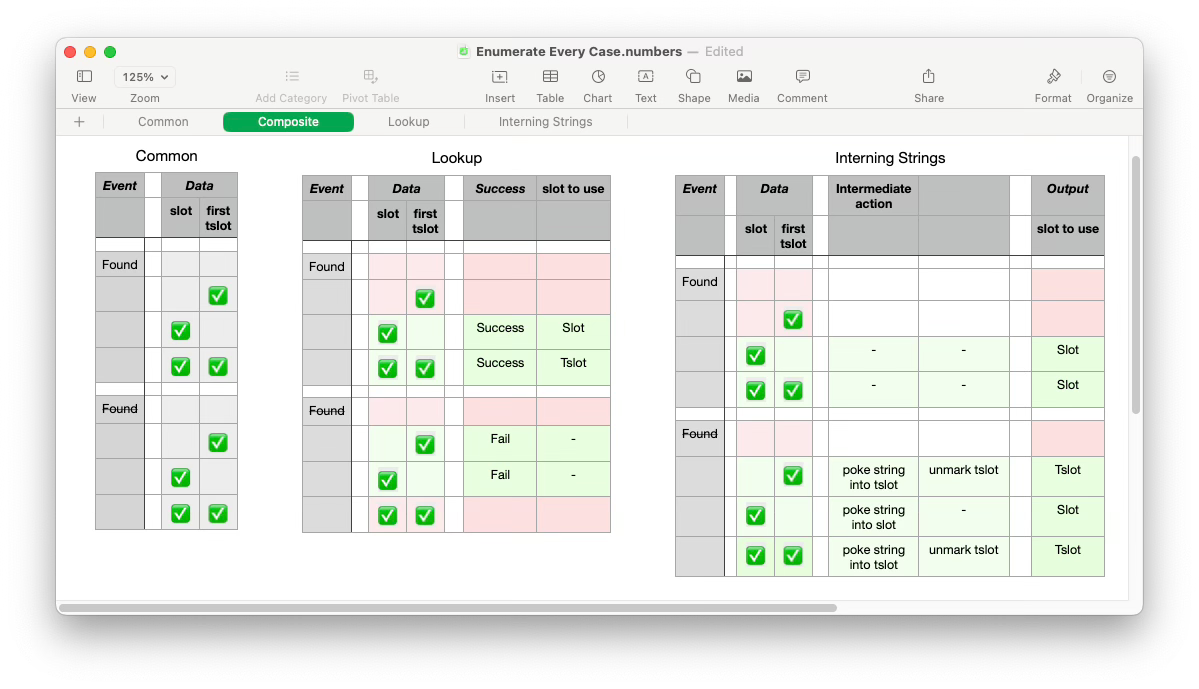
Contrast these tables with the code in the Crafting Compilers book. If I got the truth tables right, and if the code in the book is correct, the two should align. The truth tables tell the whole story, whereas one has to reverse-engineer the code to figure out what happens in every case.
[In some ways, it doesn’t matter if I got the truth tables correct. The tables show - to other humans - what I was thinking. If I got it wrong, they could more quickly point out my mistake without needing to reverse engineer what I was trying to accomplish.]
Conclusion
My conclusion is that the LEGO® block design and truth tables are better for expressing DI - Design Intent - whereas the code is productionized, optimized and ready to be shipped in a cost-efficient manner.
The PBP design looks somewhat more detailed and complicated than the text code version, but, the point of this article is that programmers can express every case very explicitly.
Wasting human brain power on optimizing code was deemed necessary in 1960, due to slow hardware and limited memory, but, I think that it should be possible to off-load many kinds of optimizations to software tools today.
I haven’t actually tested the design in this article, but, I have built a software LEGO® block design tool that I call PBP (formerly 0D). The ideas for this come from electronics schematics. Such asynchronous blocks can be built using programming languages and workflows that we have today, but, require programmers to step back and to avoid using functions for every part of a solution.
In PBP, there is only one kind of event - a mevent - which is a pair containing a port ID and a payload. Both, ports and payloads are strings. The current programming tech stack allows for finer definition of data structures, e.g. classes, for payloads, but for DI, that amount of detail is not actually necessary (again, in my opinion, tools, not humans, should optimize and reorganize data).
In PBP, all mevents cause reactions in receiving parts, although, not instantaneously like in FP. In PBP, mevents are queued (one queue per part) and the dispatcher gets to decide when a part gets to consume the first mevent in its input queue and how to react to it.
In this article, there is another kind of port/payload - a data element that doesn’t need to be dealt with immediately, but, only needs to be saved and is guaranteed to arrive before some driving event(s). This can be implemented explicitly in PBP, but, might suggest some new syntactic / semantic addition to PBP.
It should be noted that the PBP syntax in this article allows for multiple inputs and multiple outputs for parts. This treats software more like electronics rather than a clockwork mechanism constructed with functions. Note that electronics components, like ICs, are asynchronous and parallel by default. Modern software programming languages use wishful-thinking keywords like async, but, are synchronous and sequential by default. Synchronous, sequential programming languages can never express compositions of asynchronous systems. At best, such programming languages can express single nodes that react to asynchronous events within asynchronous systems. In my opinion, this is but a form of low-level “assembler” for building asynchronous systems.
Further
An example of an experimental PBP “compiler” (actually a transpiler) can be found in this repository.
On-going development of PBP tools, including a PBP kernel written in a VHLL can be found in this repository.
Harel’s Statecharts solve the state explosion problem for software state machines. The simple idea of isolation - full encapsulation of data and of control flow - is used in PBP.
See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com