
Composing Multi-Node Systems
2025-03-13

IMO, the problem to be solved is how to compose systems that contain zillions of nodes. We need “structured message passing” similar to “structured programming”. That problem decomposes into the first-order issue of data transfer between nodes. This involves various niggly issues:
Shared memory vs. private memory
Distance, e.g. on same chip vs. several time zones apart
Programming language for sender and receiver (same PL or different)
Guaranteed delivery vs. fire and forget.
Sketches of Issues and Possible Decisions
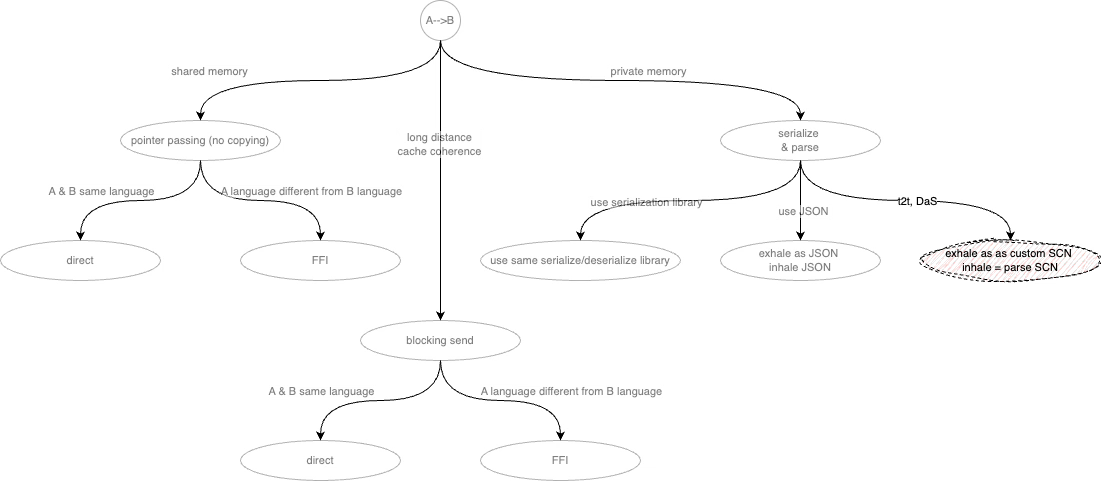
Fire and Forget

Synchronous CALL / RETURN or Asynchronous ACK/NAK

Discussion of Issues
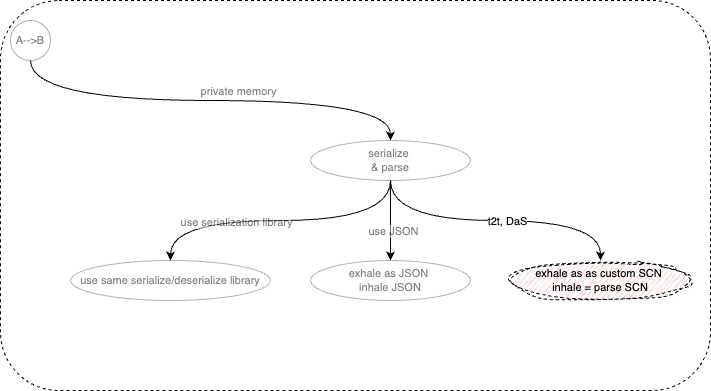
The most general solution to composing devices using many nodes is to serialize/deserialize - exhale/inhale - data, regardless of data shape.
Developing optimizations for data transfer, before we’ve solved the general case, is a bad idea, IMO.
PLs based on memory sharing and time sharing (aka “concurrency”) are such optimizations.
Worrying about data structures is just an optimization. Data structures are just an aid for helping developers create code that contains as few foot-guns as possible.
[This is all that we’ve got at present, though. Development of these techniques was built on the 1950s notion that only one CPU node can be used at once. Today’s problem is entirely different and requires new solutions, not just incremental improvements of outdated technologies].
Given this attitude, the basic question decomposes into “how to convert structured data into something that can be transferred without assuming the use of shared memory and under-the-hood cache coherence?”.
My current answer: use character strings for the data transport layer. Develop specialized solutions for each sender/receiver pair.
A generalized solution cannot possibly cover all real cases.
This leads to the question “how to make this kind of thing less painful?”. JSON is a cute first take on solving this basic problem.
I think that there is even something better - the application of pattern matching techniques to streams of characters. In fact, our current tools are very well-suited for pattern matching character streams. This is called “parsing”. But, outdated formal language theory makes building parsers too painful and implies megaprojects that last months or years. I want parsers that take tens of minutes to build. And, I want ways to exhale character streams in customized ways. Hence, “t2t”. And, I want syntax that allows composing DPUs (Distributed Processing Units) in more ways than just functions calls and simplified pipelines. Hence, DaS (Diagrams as Syntax) and 0D.
Thinking this way de-emphasizes the issue of “structured data”. In my mind, the issue of “structured data” is much, much less important than the basic problem discussed above. Given that “structured data” is a less important detail than data transfer, it is reasonable to ignore the issue and to concentrate only on the issue of making data transfer easy to specify and to use.
A side benefit of all of this is that t2t and 0D are useful in their own right. 0D ideas are being used in production at kagi.com. T2t is better than REGEXP for creating quickie bulk-editors for parsing and rewriting bracketed programming languages. I have reached the conclusion that no one needs to write a compiler again when developing a new programming language. Using t2t, one can just transpile the new programming language into some existing syntax and let the existing compiler do the rest of the heavy lifting. T2t, also, allows one to use more interesting fundamental syntactic units, e.g. parsing XML/HTML “elements” instead of just parsing ASCII characters when recognizing language phrases.
I backed into this kind of thinking by looking for ways to create compilable comments in hopes of optimizing human communications between customers and management and developers in my software consultancy. I learned how to parse software “circuits” (currently called PBP (Parts Based Programming) and/or 0D), how to parse Statecharts, how to parse Drakon diagrams, etc. I used to build graphical editors, too, but, now, I don’t need to waste brain power on that, since existing diagram editors like draw.io produce enough information in parseable form.
See Also
Email: ptcomputingsimplicity@gmail.com
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/65YZUh6Jpq
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: tarvydas.gumroad.com
Twitter: @paul_tarvydas
Substack: paultarvydas.substack.com