


Building a REPL in 2024
Towards Higher Level Syntax for Programming Languages 2024-11-12

Overview

An overview video of this article is seen below.
This experiment germinated as a little side-project in aid of building better tooling for a larger project that I’m working on. In essence, the hope was to build a REPL in about ½ hour, using tools that were already available. I’m on day 3, so the ½ goal has not been met,,, but, I’ve come across some interesting revelations, and, brainstorms along the way which make me continue to be interested in pursuing this side-project in lieu of working on the larger project (this is beginning to sound like classic procrastination 😁).
A quick screencast of the experimental REPL can be seen in this video below ...
As it stands, the REPL consists of 4 processes choreographed by a central websocket server and file watcher and compiler. In this version, the choreography code is written in Python, mostly by an LLM (Claude and ChatGPT). The websocket server and the file watcher loop are Python coroutines (“async def”)
A code editor runs in a separate window, as a separate process. When it saves data, the REPL updates the information displayed in the IDE window. In this version, the editor is draw.io[1] and the code is written as a diagram. This is a DPL - Diagrammatic Programming Language. Note that the code is first written in diagrammatic form, then compiled to text, i.e. the code is not written in text form first.
The IDE is a simple HTML+Javascript page in a local browser and connects to two websockets:
...
const to_gui = new WebSocket('ws://localhost:8765');
const from_gui = new WebSocket('ws://localhost:8766');
...
Compilation of the program is done in 2 steps:
Convert the XML (graphML[2]) saved by the editor to JSON. Cull out most graphical information leaving only semantically interesting information. Saved XML is roughly 11,000 bytes, reduced/culled version is 2,900 bytes. Current version uses an XML parser. Currently, this is done by spawning a subprocess.
Run Python code that inhales culled information, now in .json format, creates internal routing tables, instantiates components and runs the system, producing .json output. The results are sent to the IDE to be displayed. Results include output, errors, outputs from 3 probes (A, B, C) (which can be repositioned within the diagram). Currently, the Python runtime code is imported into the choreographer code. This is not strictly necessary. The next step will be to spawn a subprocess to run the compiled code.
Websocket Messages
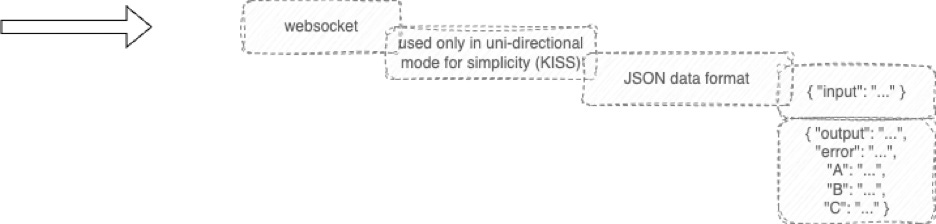
The choreographer creates 2 websockets, one for sending data to the IDE, one for receiving data from the IDE. This separation is just a divide-and-conquer approach that reduces cognitive overload when building the MVI (Minimum Viable Implementation). This can be optimized later (it turns out that further optimization is not necessary and just a waste of time).
Messages are sent in JSON format in the websockets.

The current format consists of key/value pairs - name of field, contents of field (as changed by the user, or, as to be updated by the choreographer). Future embellishments might include a richer subset of operations which can be used to create and delete fields in the browser IDE. Again, reducing cognitive load, i.e. KISS, made it faster and easier to invent the REPL system. It may turn out to be unnecessary to add baubles to the protocol and to maintain KISS simplicity...
Efficiency

It turns out that spawning subprocesses on a modern development machine (Mac mini M3, running MacOS) is “fast enough”. Delays are imperceptible to developers using the REPL to develop code. No further optimization is necessary. We can move on and use our brain power for inventing new systems instead of optimizing this system.
Observations and Conclusions
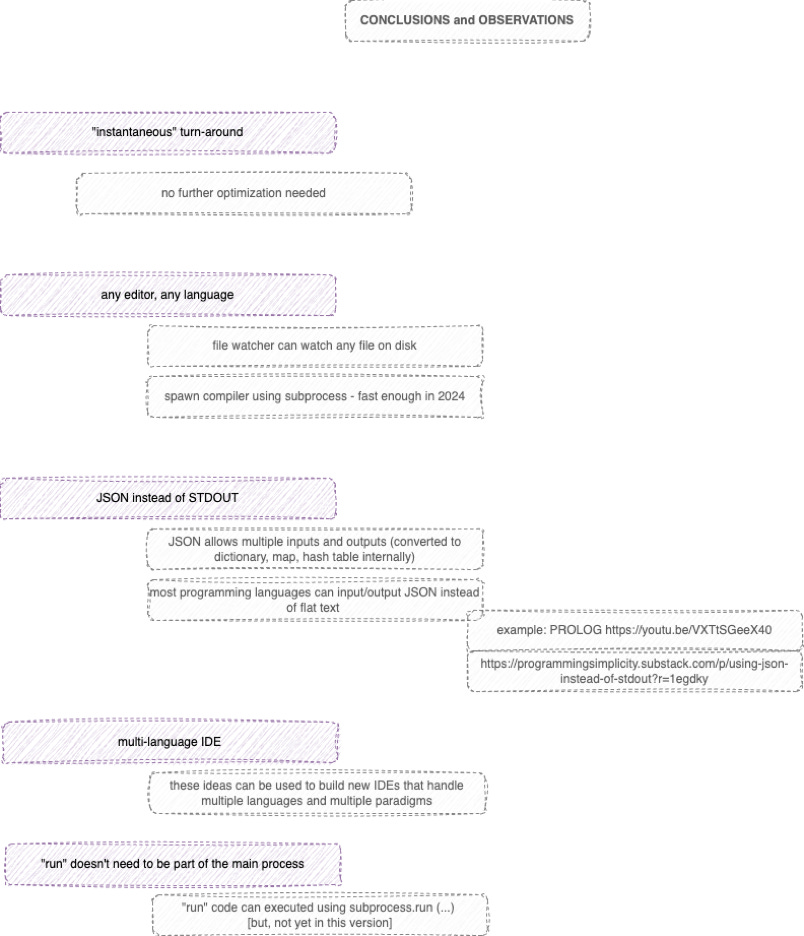
Fast Enough
Turn-around is “instantaneous” with respect to human perception. At first blush, the design looks to be inefficient, but, the only kind of efficiency question is “is this fast enough for developers to use on development machines?”. There is no need to optimize the system beyond the point that the system become “fast enough” to use. This was not the case in 1950. Machines, though, are much faster and much cheaper and much more ubiquitous in 2024, i.e. old-fashioned ideas about “efficiency” are no longer valid. In 2024, there are at least 2 kinds of efficiency:
Is it fast enough for developers to use, on development hardware?
Is it fast enough for non-developers to use, on cheaper hardware?
In 2024, developers can begin each project by building an MVI - Minimum Viable Implementation - using whatever tools and libraries are available. When such MVIs are measured and proven to be too slow for production use, they can be further optimized by production engineers. Most modern programming languages, like Rust, Python, etc. are geared towards production engineering and optimization. More flexible languages and IDEs can be developed and used for design engineering.
Other Editors and Languages
The file watching loop is quite general and could be used in conjunction with any editor, as long as the editor saves information in files on disk accessible by the choreographer program. Theoretically, text editors, like emacs, vim, vscode, could be used in this system along with compilers for the respective languages, but, most existing text-based languages are supported by elaborate (read: overly-complicated) tools for running and debugging. What is shown in this experiment is that it is “easy” to build REPLs and debuggers for new languages which don’t yet have full-blown, elaborate support tools.
Many Languages, Many Paradigms
What is, also, hinted at is that an IDE could use many different programming languages and paradigms - doing so would lead to a change in programming workflow (for the better, in my opinion).
JSON Instead of STDOUT
It is observed that UNIX-style stdout is too “flat” for modern, component-based systems.
Instead of raw output from programs, we want tagged output from programs. Tags allow us to produce output destined for many ports, instead of just one or two, like stdout and stderr.
This experiment shows that JSON is a widely available format that can support component-based design and debugging. Even “outré” languages, like PROLOG[3] support JSON I/O[4]. On the surface, the JSON format appears to be “inefficient”, but, in practice JSON appears to be “efficient enough” for building REPLs, at least those running on the same development machines.
Speculation: Replacing Some Parts By Target Hardware
Can this architecture be used to cross-compile to other kinds of target hardware?
For example, if we leave everything as is, but replace the ‘run’ code by an Xbox or cheap Arduino, do we gain the ability to develop code using a REPL, then test the code on a simpler / cheaper target?
This isn’t a particularly new idea, but, this kind of arrangement might make implementation of the idea simpler.
Speculation: Spawning Another Process for ‘Run’
In this experiment, the code for running a compiled program is embedded in the choreographer process.
Can we simply spawn yet another process for running the code? Will this be “efficient enough”?
This experiment suggests that adding yet another process will not harm turn-around time, i.e. the REPL will still feel like it runs instantaneously.
This speculation suggests yet another experiment.
Code Repository
The code for this experiment is in the github public repository https://github.com/guitarvydas/dwrepl.
See Also
References: https://guitarvydas.github.io/2024/01/06/References.html
Blog: https://guitarvydas.github.io
Videos: https://www.youtube.com/@programmingsimplicity2980
Discord: https://discord.gg/qtTAdxxU
Leanpub: [WIP] https://leanpub.com/u/paul-tarvydas
Gumroad: https://tarvydas.gumroad.com
Twitter: @paul_tarvydas
Bibliography
[1] Draw.io from https://app.diagrams.net
[2] GraphML from http://graphml.graphdrawing.org
[3] SWIPL from https://www.swi-prolog.org
[4] Read and Write JSON in PROLOG from